1. TF训练后量化概要
TensorFlow Lite支持对已训练好的模型进行训练后量化(Post-training quantization)。具体来说,TFLite支持对表1所列的38种Ops1进行训练后量化,这些Ops基本涵盖了当前的主流深度学习模型。
| ADD | ARG_MAX | AVERAGE_POOL_2D |
|---|---|---|
| BATCH_TO_SPACE_ND | CONCATENATION | CONV_2D |
| DEPTHWISE_CONV_2D | EQUAL | FULLY_CONNECTED |
| GATHER | GREATER | GREATER_EQUAL |
| L2_NORMALIZATION | LESS | LESS_EQUAL |
| LOGISTIC | LOG_SOFTMAX | MAXIMUM |
| MAX_POOL_2D | MEAN | MINIMUM |
| MUL | NOT_EQUAL | PAD |
| PADV2 | QUANTIZE | RESHAPE |
| RESIZE_BILINEAR | SHAPE | SLICE |
| SOFTMAX | SPACE_TO_BATCH_ND | SPACE_TO_DEPTH |
| SQUEEZE | SUB | SUM |
| TANH | TRANSPOSE |
TensorFlow Lite提供了多种训练后量化方式以供用户选择,不同的量化方式所带来的收益如表2所示。用户可根据图1所示的决策树进行训练后量化方式的选择。
| Technique | Benefits | Hardware |
|---|---|---|
| Weight-only quantization | 4x smaller, 2-3x speedup, accuracy | CPU |
| Full integer quantization | 4x smaller, 3x+ speedup | CPU, Edge TPU, etc. |
| Float16 quantization | 2x smaller, potential GPU acceleration | CPU/GPU |
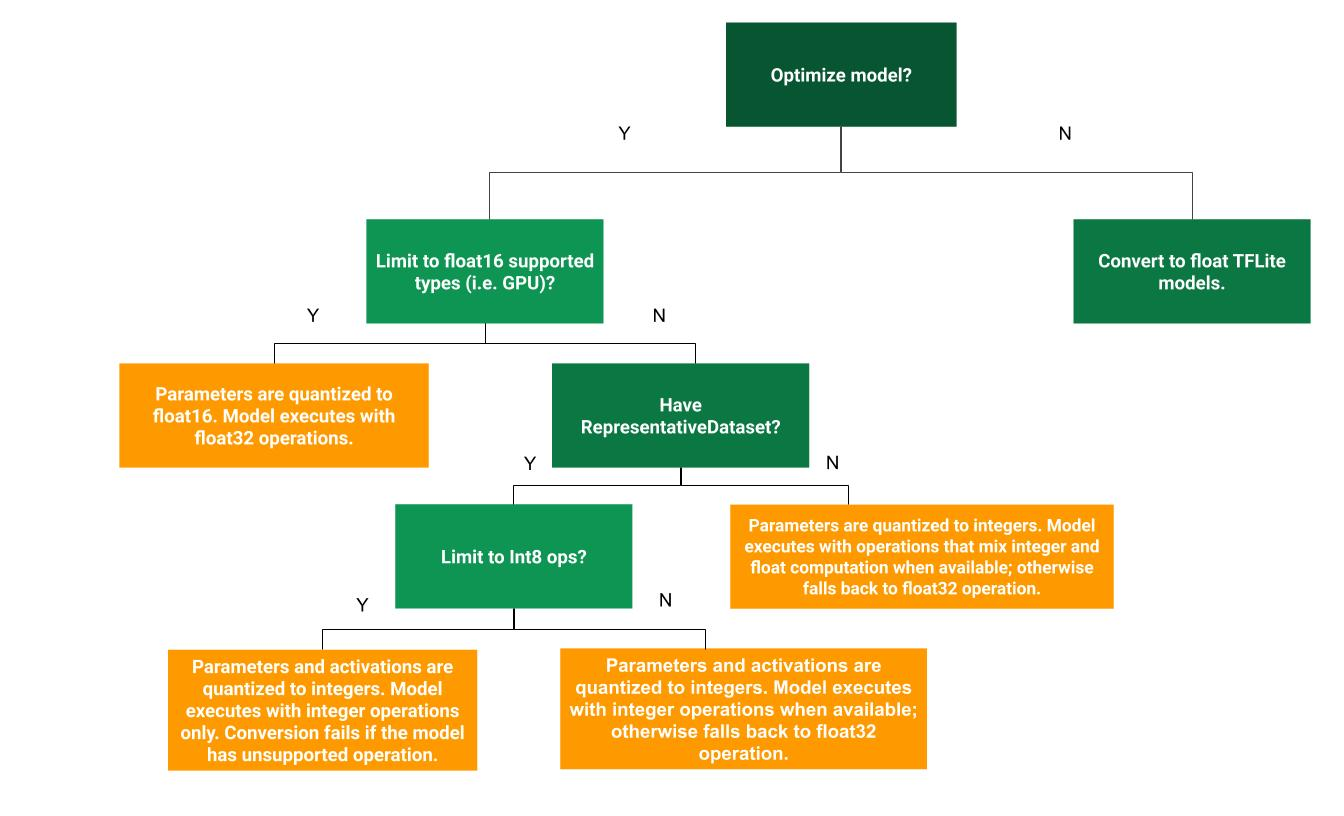
图1 训练后量化方式选择依据决策树
2. TF训练后量化代码结构
2.1 Python部分代码结构介绍
1
2
3
4
5
6
7
tensorflow
└── tensorflow
└── lite
└── python
└── lite.py # TFLiteConverter.convert()调用_calibrate_quantize_model方法启动训练后量化
└── optimize
└── calibrator.py # 使用浮点模型进行校准并调用CalibrationWrapper提供的接口进行训练后量化
2.2 C++部分代码结构介绍
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
tensorflow
└── tensorflow
└── lite
└── python
└── optimize
└── calibration_wrapper.cc # CalibrationWrapper作为python层调用c++层训练后量化功能的接口包装类
└── calibration_wrapper.h
└── tools
└── optimize
└── calibration
├── calibration_common.h # 训练后量化使用的一些类型定义
├── calibration_logger.h # 记录tensor最小最大值的Logger类
├── calibration_reader.cc # 根据Logger中记录的最小最大值为模型的每个kernel的输入输出激活tensor设置quantization属性(即最小最大值)
├── calibration_reader.h
├── calibrator.cc # 主要用于构建可记录校准数据的LoggingInterpreter
├── calibrator.h
├── logging_op_resolver.cc # 设置kernel调用的评估函数包装器
├── logging_op_resolver.h
├── node_info_delegate.cc # 用于构建一个从TfLiteNode*到OperatorInfo的映射
└── node_info_delegate.h
├── model_utils.cc # 定义模型修改工具函数,如创建Dequantize、Quantize算子、创建tensor、检测tensor是否存在buffer(weights存在buffer)等
├── model_utils.h
├── operator_property.cc # 定义了算子的属性,如该算子是否可量化、算子的不同输入使用何种量化方式(分通道量化与否、对称量化与否)
├── operator_property.h
├── quantization_utils.cc # 定义了一些量化函数,如QuantizeWeight、QuantizeActivation、SymmetricQuantizeTensor、SymmetricQuantizeTensorPerChannel和GetAsymmetricQuantizationParams等。
├── quantization_utils.h
├── quantize_model.cc # 对模型进行量化的入口,QuantizeModel函数为模型的权重/输入/输出加上了量化sacle和zero_pnt,并修改了计算图的结构,如加上了一些
├── quantize_model.h
├── quantize_weights.cc # 将权重量化到int8或者fp16,该文件在仅量化权重时使用(其应该为TFLite第一版仅量化模型权重时编写的代码,在既量化权重又量化激活的代码逻辑中并没有使用该文件中定义的函数)。
└── quantize_weights.h
3. 图解TF训练后量化代码逻辑
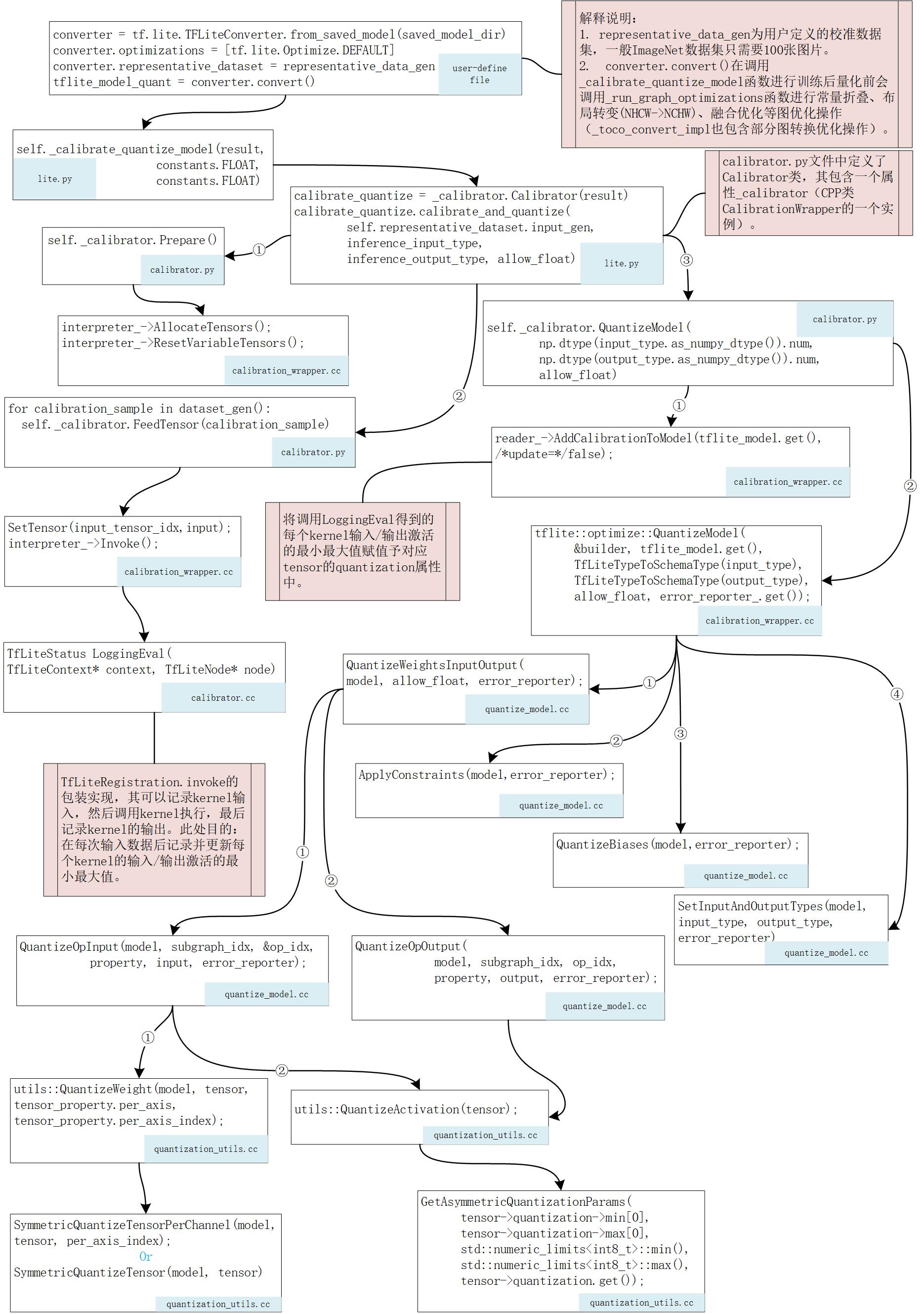
图2 TensorFlow训练后量化代码逻辑流程
4. TFLite训练后量化使用的格式说明
TensorFlow Lite使用如下公式将fp32浮点值量化8-bit整型:
\[\text { real_value }=\left(\text { int8_value } - \text {zero_point}\right) \times \text {scale}\]- 对卷积类Op的权重使用per-axis(亦per-channel)量化,对其他的Op权重使用per-tensor量化,且将它们对称量化到[-127, 127]范围内(此时整型零点zero_point即对应到浮点0值)。
- 每个Op的输入/输出激活tensor使用非对称量化到 [-128, 127]范围内,此时整型零点zero_point取值范围也为[-128, 127]。
4.1 int8 VS uint8
TensorFlow Lite在8-bit量化上主要优先使用int8数据类型。这对于对称量化来说是十分有益的,因为此时使用int8可以将整型零点zero_point精确映射到浮点0值。除此之外,TensorFlow Lite的许多后端对\(int8 \times int8\)的累积运算进行了许多优化。
4.2 per-axis量化 VS per-tensor量化
per-tensor量化意味着整个tensor仅有一个scale和一个整型零点zero_point。per-axis量化意味着在量化维度上每个slice分片均有一个scale和对应的整型零点zero_point。通常来说,卷积权重的输出通道即为量化维度,这可以更加细化量化粒度使得模型精度损失更小。TFLite目前支持对Conv2d以及DepthwiseConv2d的权重进行per-axis量化。
4.3 对称量化 VS 非对称量化
在TFLite的训练后量化实现中,激活采用的是非对称量化,而权重采用的是对称量化。
- 非对称量化(激活):整型零点zero_point是int类型,且取值范围在[-128, 127]。许多激活本质上就是非对称的,并且虽然其整型零点zero_point可能不为0,但在计算上所带来的额外开销并不大。非对称以微小的零点计算开销为代价换来更多的二进制bit精度。之所以说非零的整型零点带来的计算开销很低,是因为激活仅与常量权重相乘,常量零点值与常量权重的计算可提前一次性完成。
- 对称量化(权重):对称量化可以强制整型零点zero_point的值为0。与权重相乘的输入激活是动态变化的,这意味着如果权重的零点不为0的话,激活与权重零点相乘的运行时开销是不可避免的。而强制权重零点为0,则可避免这一计算开销。
\(A\)是 \(m \times n\)量化激活矩阵, \(B\)是 \(n \times p\)量化权重矩阵。假定将\(A\)的第j行\(a_j\)与\(B\)的第k列\(b_k\)相乘。量化整型值以及整型零点值分别为\(q_a, z_a\)以及\(q_b, z_b\)。计算公式如下:
\[\begin{array}{**l**} a_{j} \cdot b_{k} &=\sum_{i=0}^{n} a_{j}^{(i)} b_{k}^{(i)} \\ &=\sum_{i=0}^{n}\left(q_{a}^{(i)}-z_{a}\right)\left(q_{b}^{(i)}-z_{b}\right) \\ &=\sum_{i=0}^{n} q_{a}^{(i)} q_{b}^{(i)}-\sum_{i=0}^{n} q_{a}^{(i)} z_{b}-\sum_{i=0}^{n} q_{b}^{(i)} z_{a}+\sum_{i=0}^{n} z_{a} z_{b} \end{array}\]- \(\sum_{i=0}^{n} q_{a}^{(i)} q_{b}^{(i)}\)的计算是不可避免的,因为它是输入激活与权重的点乘运算。
- \(\sum_{i=0}^{n} q_{b}^{(i)} z_{a}+\sum_{i=0}^{n} z_{a} z_{b}\)均有常量间的计算组成,在每次的推理调用期间均是相同的,所以可以提前一次性计算好。
- \(\sum_{i=0}^{n} q_{a}^{(i)} z_{b}\)需要在每次推理时计算,因为激活每次推理都是动态变化的。通过强制权重使用对称量化(\(z_b = 0\)),这一步的计算开销即可被移除掉。
5. TFLite训练后量化示例
- 仅对权重进行训练后量化的tf官方示例:post_training_quant.ipynb。
- 对权重和激活同时进行训练后量化的tf官方示例:post_training_integer_quant.ipynb。
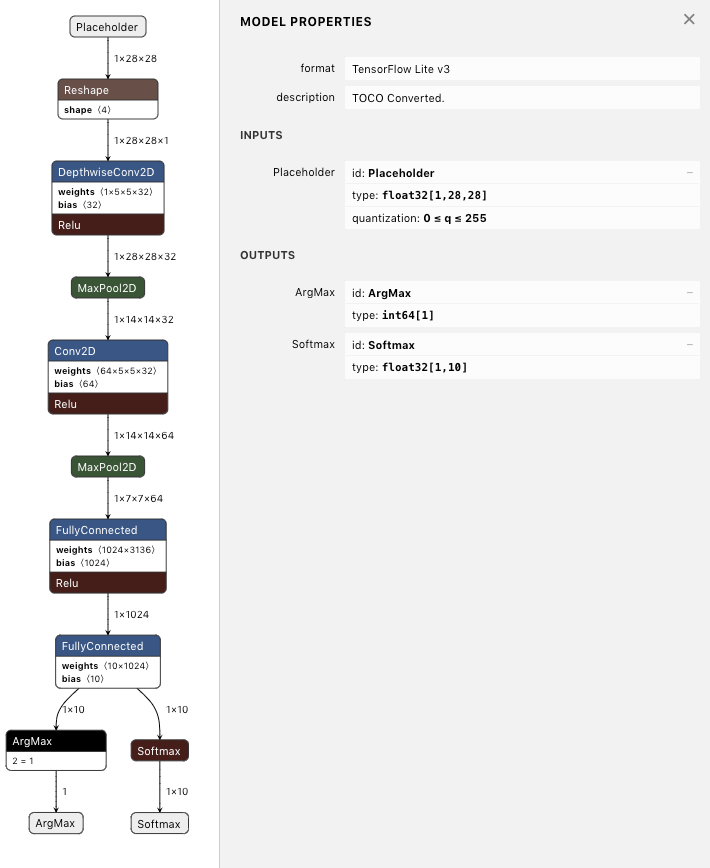
图3 使用训练后量化前的原始模型图
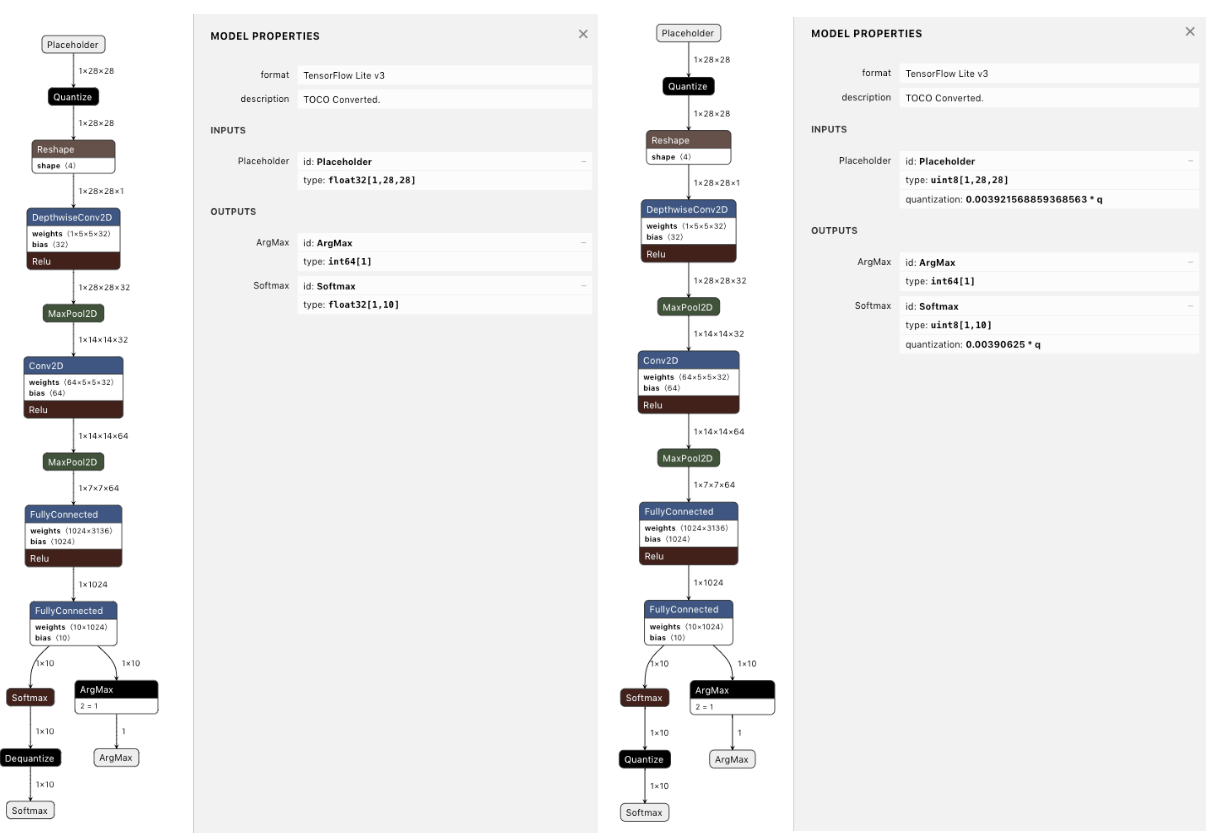
图4 使用训练后量化后的模型图(左:输入/输出为float类型,右:输入/输出为uint8类型)
备注:
- TFLite的Quantize算子可实现fp32到int8/uint8/int16的量化转换、int8到int8/uint8的量化转换以及uint8到int8/uint8的量化转换等操作。
- TFLite的Deuantize算子可实现uint8到fp32的反量化转换、int8到fp32的反量化转换、int16到fp32的反量化转换以及fp16到fp32的反量化转换等操作。
6. TFLite量化效果
- 性能(Latency)
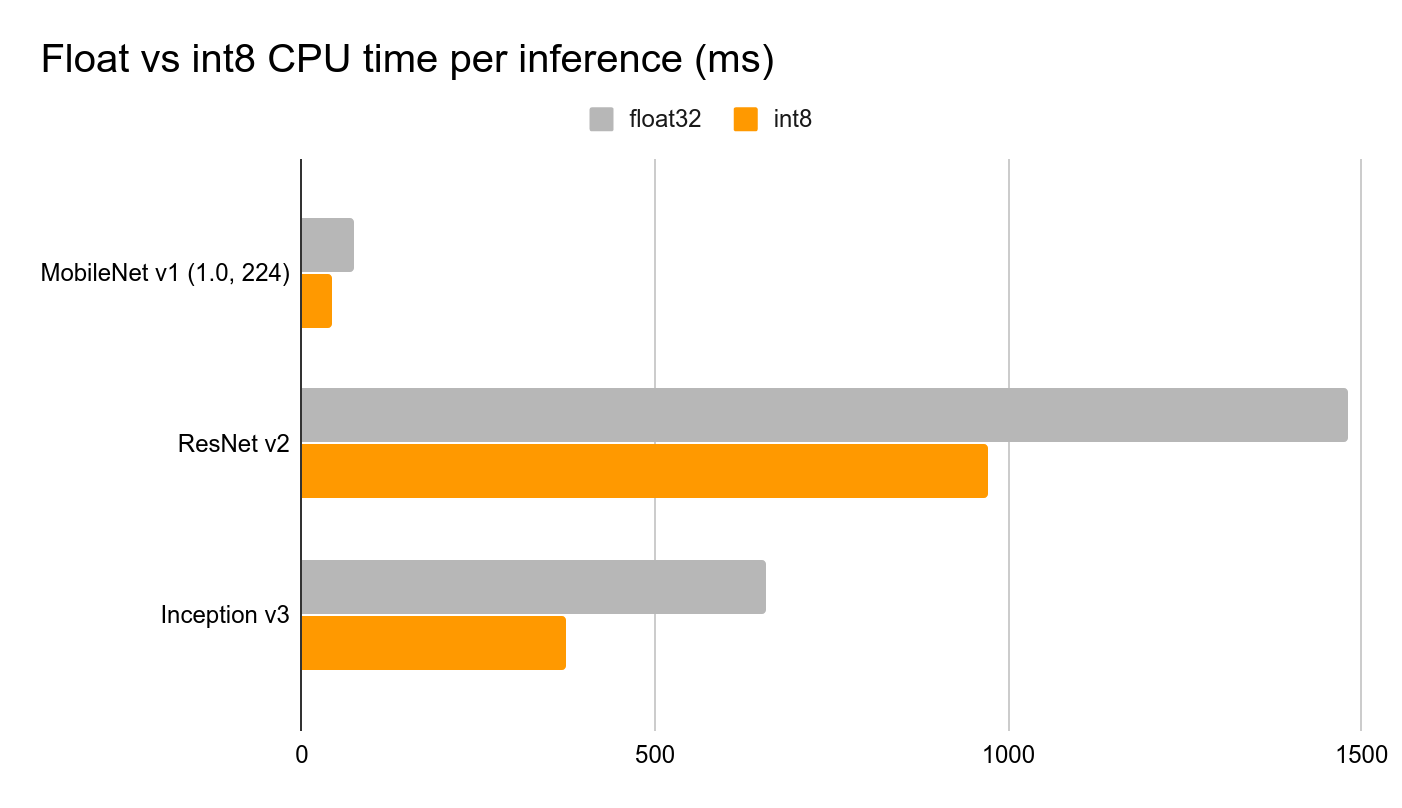
与对应的FP32模型相比,量化模型的CPU性能加速比可达2–4\(\times\),且模型大小仅为原FP32的1/4。
- 精度(Accuracy)
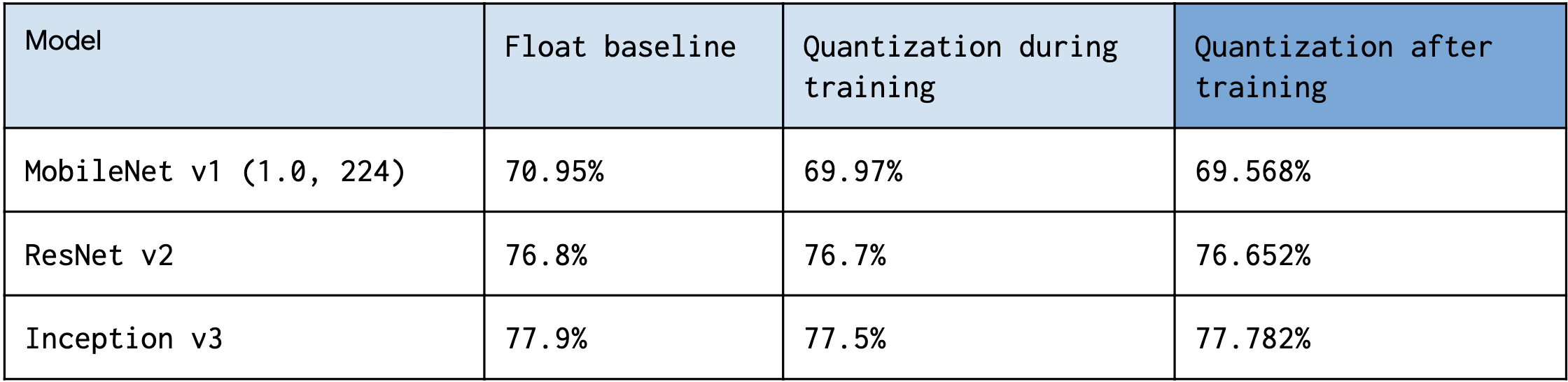
训练后量化仅使用了ImageNet数据集中的100张校准图片,全整型量化模型的精度损失在1%以内。
参考资料
- Post-training quantization in TensorFlow官方使用文档
- TensorFlow Lite 8-bit quantization specification
- Introducing the Model Optimization Toolkit for TensorFlow
- TensorFlow Model Optimization Toolkit — Post-Training Integer Quantization
- 仅对权重进行训练后量化的tf官方教程
- 对权重和激活同时进行训练后量化的tf官方教程
- Pre-trained models optimized to work with TensorFlow Lite