1. TF量化训练概要
TensorFlow提供对量化训练(Quantization-aware training1)的支持,且主要是对Conv2D|MatMul|DepthwiseConv2dNative三类op做FakeQuant量化。除此之外,与上述三类Op相关(隶属于下文描述的某一pattern)的Relu|Relu6|Identity以及Add|AddV2等Op也会被FakeQuant量化。
2. TF量化训练代码结构
2.1 Python部分代码结构介绍
1
2
3
4
5
6
7
8
9
10
11
12
tensorflow
└── tensorflow
└── contrib
└── quantize
└── python
├── common.py # 一些通用工具函数,如`RerouteTensor`函数可将tensor1的consumers都更新为以tensor0作为输入。
├── fold_batch_norms.py # 实现BN折叠功能,即将conv/fc之后的bn折叠进conv/fc中。
├── graph_matcher.py # 根据用户定义的pattern在图中寻找对应的子图,其中`OpTypePattern`使用递归定义一种树形结构的pattern。
├── input_to_ops.py # 定义了辅助工具类`InputToOps`,其用于维护一个map,该map将每个tensor的名称映射到以该tensor为输入的所有op。
├── quant_ops.py # 定义了各种FakeQuant层,包括FixedQuantize、LastValueQuantize和MovingAvgQuantize等,底层均使用FakeQuantWithMinMaxVarsOp等op实现。
├── quantize.py # 根据定义的patern在输入graph中匹配子图,匹配成功后将FakeQuant层插入到相应位置。
└── quantize_graph.py # tf量化训练的对外API,主要用于改写输入graph以插入量化训练操作逻辑,包括`create_training_graph`和`create_eval_graph`等API。
2.2 C++部分代码结构介绍
1
2
3
4
5
6
7
tensorflow
└── tensorflow
└── core
└── kernels
├── fake_quant_ops.cc # 包括FakeQuant等类型算子的实现,包括FakeQuantWithMinMaxVars的前反向Op和FakeQuantWithMinMaxVarsPerChannel的前反向Op。
├── fake_quant_ops_functor.h # 包括FakeQuant算子的仿函数定义,即FakeQuant算子的具体计算逻辑,包括FakeQuantWithMinMaxVarsFunctor等。
└── fake_quant_ops_gpu.cu.cc # FakeQuant算子的仿函数针对GPU设备的特化实现。
3. 图解TF量化训练代码逻辑
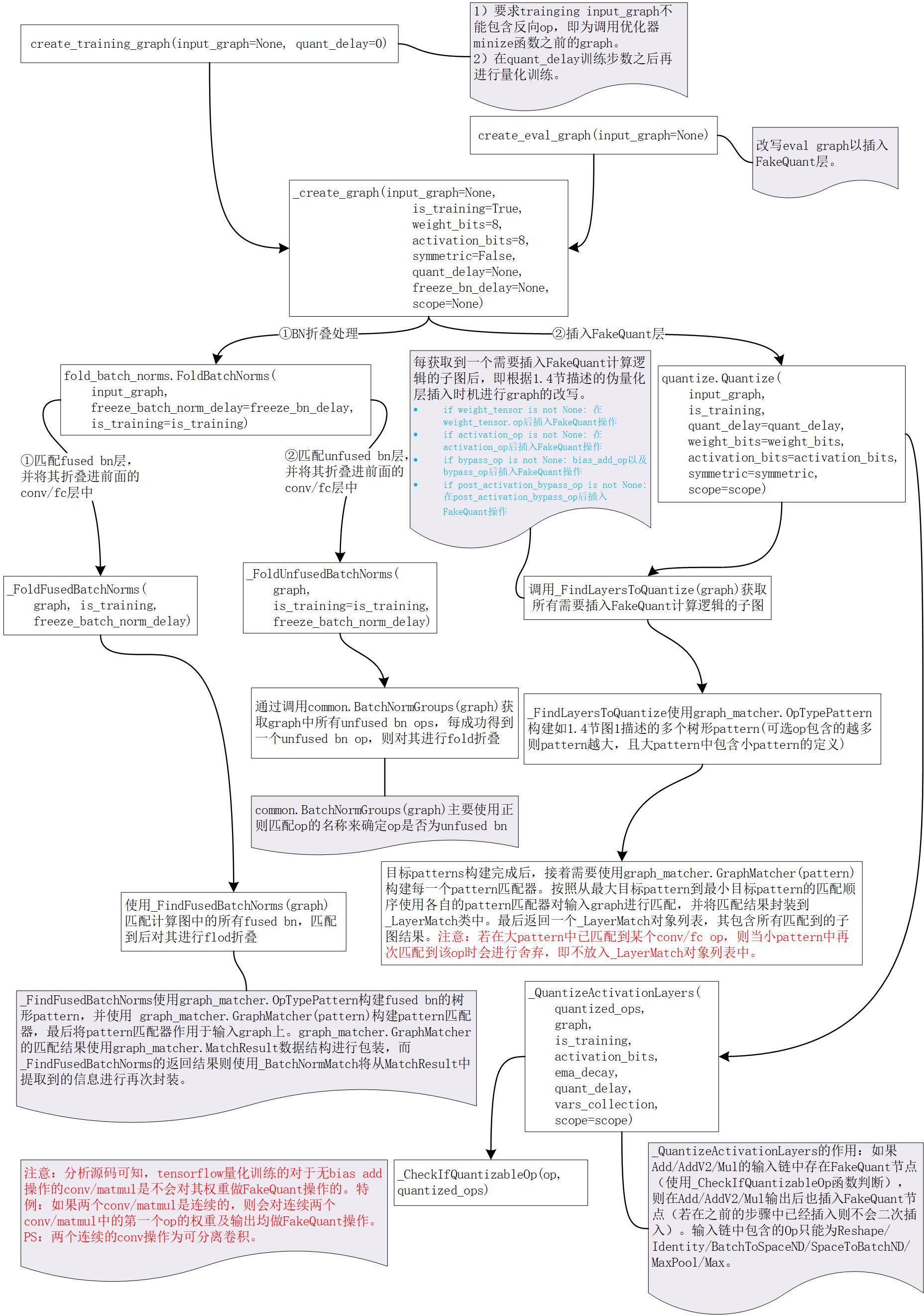
4. TF量化训练匹配pattern描述
TensorFlow量化训练的实现主要在前向计算图2中寻找如图1所示的pattern,其中紫色椭圆表示的op是必须匹配的,而黄色椭圆表示的op是可选匹配的。
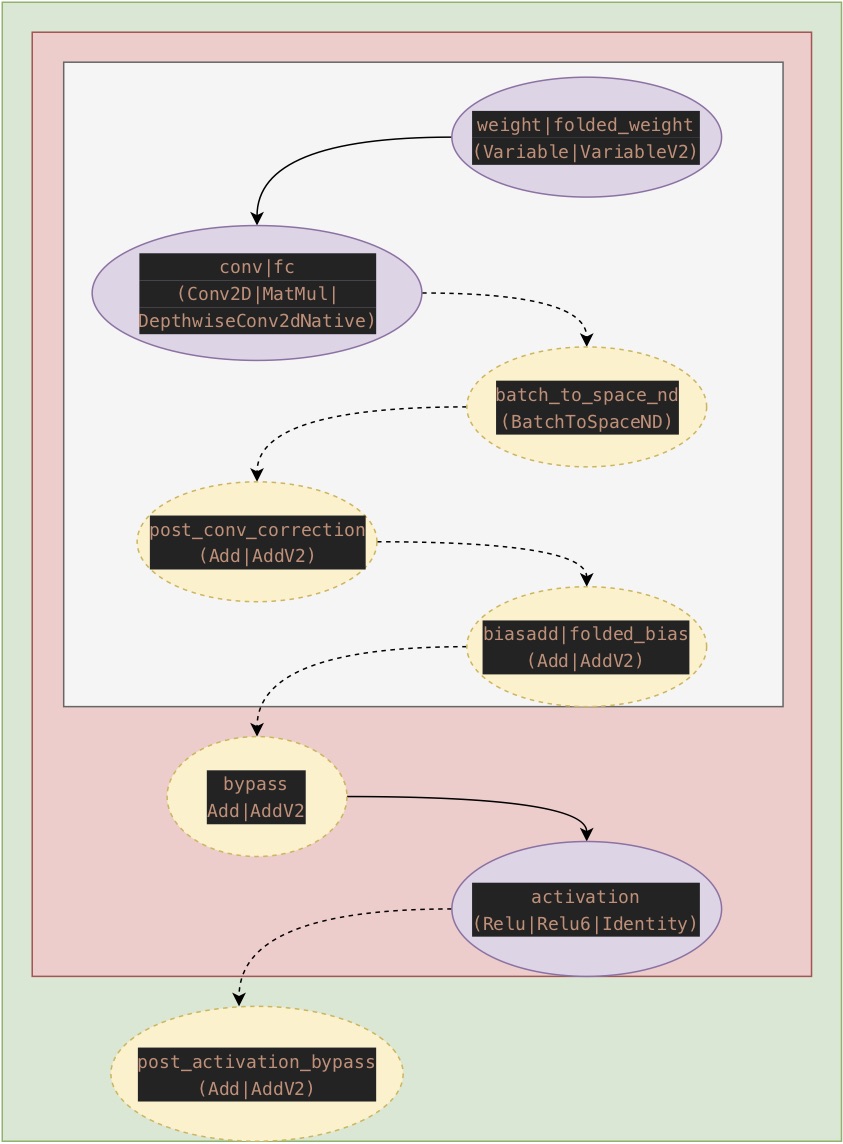
图1 TensorFlow量化匹配pattern
插入FakeQuant计算逻辑的时机描述如下:
- 若匹配到
Conv2D|MatMul|DepthwiseConv2dNative,则对其weights进行FakeQuant量化。 - 若匹配到
Relu|Relu6|Identity,则对其输出进行FakeQuant量化。 - 若匹配到bypass
(Add|AddV2,如残差相加),则对其输入和输出进行FakeQuant量化。注意:若输出为激活操作则不会bypass的输出插入FakeQuant Op,因为推理阶段会将激活操作融合到Add Op中。 - 若匹配到post_activation_bypass
(Add|AddV2,如先进行激活操作再残差相加),则对其输出进行FakeQuant量化。注意:因为要求post_activation_bypass前必须存在activation,而activation的输出已经做了FakeQuant量化,所以此处相当于对post_activation_bypass的输入和输出均进行了FakeQuant量化。
规则匹配顺序为先匹配大pattern再匹配小pattern。具体匹配pattern示例如下:
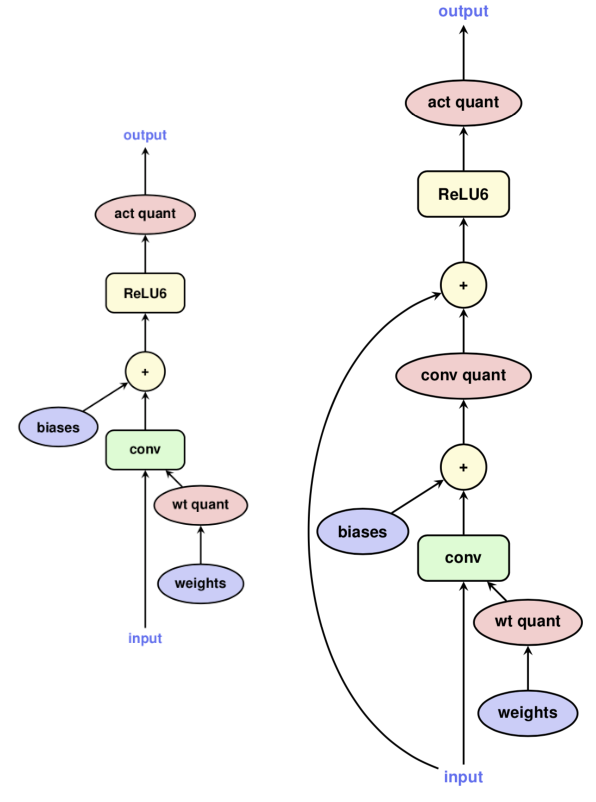
图2 匹配pattern示例(左为常规conv,右为带bypass的conv)
5. TF量化训练FakeQuant的实现
TensorFlow中FakeQuant逻辑主要通过FakeQuantWithMinMaxVarsOp和FakeQuantWithMinMaxVarsPerChannelOp两个Op进行实现。根据创建Op时是否设置了narrow_range属性为True,将fp32矩阵映射到0~255(narrow_range==False)或者1~255(narrow_range==True)。其中,对于权重使用的是1~255量化范围,而激活使用的是0~255范围。量化转换公式如下:
FakeQuantWithMinMaxVarsOp实现伪代码(前向计算逻辑):- 通过输入的待量化tensor的浮点最小值\(f_{min}\)和浮点最大值\(f_{max}\)以及uint8整型最小值\(q_{min}\)(0或1)和uint8整型最大值\(q_{max}\)(255)计算\(scale\)、\(nudged\_zero\_point\)、\(nudged\_min\) 和 \(nudged\_max\):
\(\begin{align*}
& scale = \frac{fmax - fmin}{qmax - qmin} \tag{1} \\
& zero\_point\_from\_min = qmin - \frac{fmin}{scale} \tag{2}
\end{align*}\)
\(nudged\_zero\_point =
\begin{cases}
q_{min}, \\
\quad (\text{if} \quad zero\_point\_from\_min \lt q_{min}) \\
q_{max}, \\
\quad (\text{if} \quad zero\_point\_from\_min \gt q_{max}) \\
round(zero\_point\_from\_min), \\
\quad (\text{if} \quad zero\_point\_from\_min \in [q_{min}, q_{max}])
\end{cases} \tag{3}\)
\(\begin{align*}
& nudged\_min = (q_{min} - nudged\_zero\_point) \times scale \tag{4} \\
& nudged\_max = (q_{mmax} - nudged\_zero\_point) \times scale \tag{5}
\end{align*}\)
注意:待量化tensor的浮点最小值\(f_{min}\)和浮点最大值\(f_{max}\)是
FakeQuantWithMinMaxVarsOp的输入,它们是由其他Op计算好的。 - 将待量化tensor的每个元素值均夹逼到\(nudged\_min\)和\(nudged\_max\)之间,即通过
tensor.cwiseMin(nudged_max).cwiseMax(nudged_min)语句完成。这样可以保证浮点0一定会严格映射到一个整数,这对于0-padding到卷积尤为重要。 - 使用如下公式对待量化tensor进行FakeQuant操作: \(tensor_i = floor(\frac{tensor_i - nudged\_min}{scale} + 0.5f) * scale + nudged\_min\)
- 通过输入的待量化tensor的浮点最小值\(f_{min}\)和浮点最大值\(f_{max}\)以及uint8整型最小值\(q_{min}\)(0或1)和uint8整型最大值\(q_{max}\)(255)计算\(scale\)、\(nudged\_zero\_point\)、\(nudged\_min\) 和 \(nudged\_max\):
\(\begin{align*}
& scale = \frac{fmax - fmin}{qmax - qmin} \tag{1} \\
& zero\_point\_from\_min = qmin - \frac{fmin}{scale} \tag{2}
\end{align*}\)
\(nudged\_zero\_point =
\begin{cases}
q_{min}, \\
\quad (\text{if} \quad zero\_point\_from\_min \lt q_{min}) \\
q_{max}, \\
\quad (\text{if} \quad zero\_point\_from\_min \gt q_{max}) \\
round(zero\_point\_from\_min), \\
\quad (\text{if} \quad zero\_point\_from\_min \in [q_{min}, q_{max}])
\end{cases} \tag{3}\)
\(\begin{align*}
& nudged\_min = (q_{min} - nudged\_zero\_point) \times scale \tag{4} \\
& nudged\_max = (q_{mmax} - nudged\_zero\_point) \times scale \tag{5}
\end{align*}\)
注意:待量化tensor的浮点最小值\(f_{min}\)和浮点最大值\(f_{max}\)是
FakeQuantWithMinMaxVarsGradientOp实现伪代码(反向计算逻辑):- 根据输入的浮点最小值\(f_{min}\)和浮点最大值\(f_{max}\)以及uint8整型最小值\(q_{min}\) (0或1)和uint8整型最大值\(q_{max}\)(255)计算\(nudged\_min\)和\(nudged\_max\),计算过程已于
FakeQuantWithMinMaxVarsOp中进行了描述。 - 生成mask矩阵\(between\_nudged\_min\_max\),其维度shape与输入梯度相同。该mask矩阵元素值的计算过程:如果输入(即input)的元素值大小在\([nudged\_min, nudged\_max]\)范围内,则其对应的mask值为1,反之为0。 根据链式法则计算input的输出梯度: \(输出梯度(input) =上层传入的输入梯度 \times between\_nudged\_min\_max\)。
- 生成mask矩阵 \(below\_min\),其维度shape与输入梯度相同。该mask矩阵元素值的计算过程:如果输入(即input)的元素值小于 \(nudged\_min\) ,则其对应的mask值为1,反之为0。 根据链式法则计算min的输出梯度:\(输出梯度(min) = \sum(上层传入的输入梯度 \times below\_min\))。
- 生成mask矩阵 \(above\_max\),其维度shape与输入梯度相同。该mask矩阵元素值的计算过程:如果输入(即input)的元素值大于 \(nudged\_max\) ,则其对应的mask值为1,反之为0。 根据链式法则计算max的输出梯度:\(输出梯度(max) = \sum(上层传入的输入梯度 \times above\_max\))。
- 根据输入的浮点最小值\(f_{min}\)和浮点最大值\(f_{max}\)以及uint8整型最小值\(q_{min}\) (0或1)和uint8整型最大值\(q_{max}\)(255)计算\(nudged\_min\)和\(nudged\_max\),计算过程已于
6. TF量化训练中的BN折叠
TensorFlow在插入FakeQuant Op前会进行BatchNormFold操作,主要是为了实现对BatchNorm的FakeQuant量化。
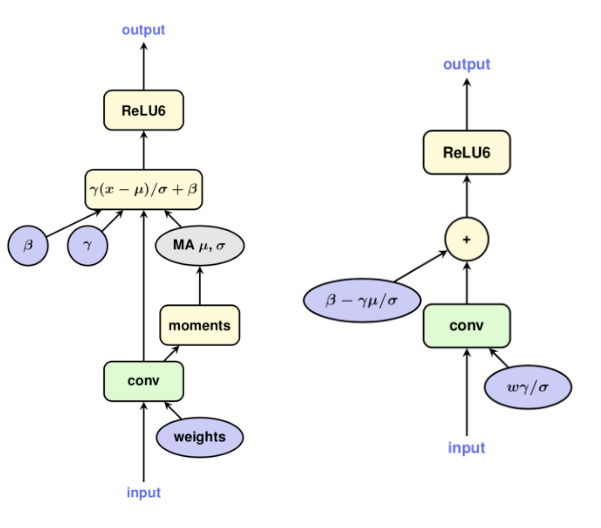
图3 带batch normalization的卷积层
(左为training graph,右为inference graph)
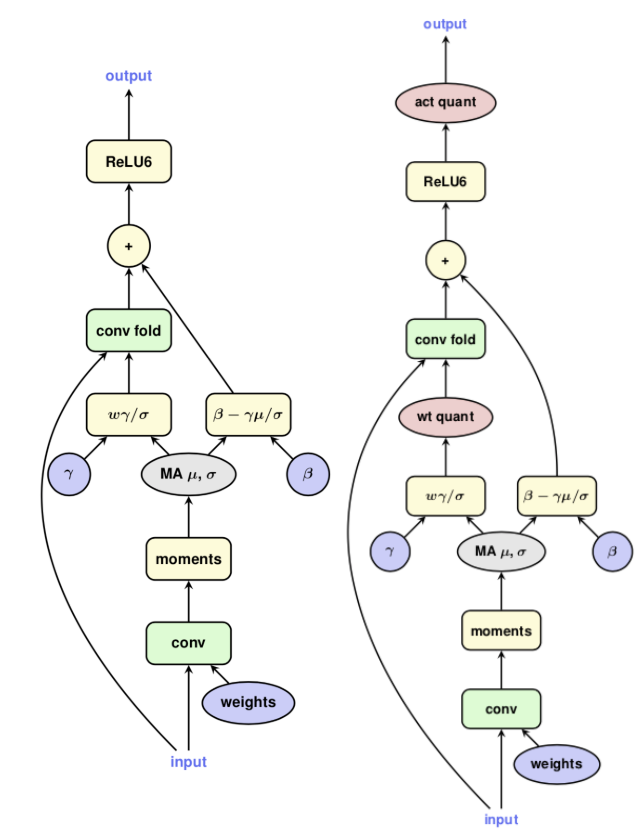
图4 带batch normalization的卷积层
(左为training graph且folded,右为training graph且folded and quantized)
对比图3和图4可知,TensorFlow采用的BN折叠主要是将一个conv分化成两个conv,其中原来的conv仅仅是为了求取batch normalization操作的输出均值和方差,利用每次更新得到的均值和方差实现对第二个conv的BN折叠计算,并且第二个conv的输出才真正作为conv+bn之后下一层Op的输入。
7. TF量化训练使用示例
- 改写training graph以获取fake quantized training graph
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# Build forward pass of model.
loss = tf.losses.get_total_loss()
# Call the training rewrite which rewrites the graph in-place with
# FakeQuantization nodes and folds batchnorm for training. It is
# often needed to fine tune a floating point model for quantization
# with this training tool. When training from scratch, quant_delay
# can be used to activate quantization after training to converge
# with the float graph, effectively fine-tuning the model.
g = tf.get_default_graph()
tf.contrib.quantize.create_training_graph(input_graph=g,
quant_delay=2000000)
# Call backward pass optimizer as usual.
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
optimizer.minimize(loss)
- 改写eval graph以获取fake quantized eval graph
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# Build eval model
logits = tf.nn.softmax_cross_entropy_with_logits_v2(...)
# Call the eval rewrite which rewrites the graph in-place with
# FakeQuantization nodes and fold batchnorm for eval.
g = tf.get_default_graph()
tf.contrib.quantize.create_eval_graph(input_graph=g)
# Save the checkpoint and eval graph proto to disk for freezing
# and providing to TFLite.
with open(eval_graph_file, ‘w’) as f:
f.write(str(g.as_graph_def()))
saver = tf.train.Saver()
saver.save(sess, checkpoint_name)
注意:改写training graph和eval grap两步操作建议放在不同的python文件中执行,因为create_training_graph和create_eval_graph对输入graph的改写均是in-place的(需避免tf.get_default_graph()使用时的相互影响)。
- 创建frozen graph(TensorFlow Lite工具链所需)
1
2
3
4
freeze_graph \
--input_graph=eval_graph_def.pb \
--input_checkpoint=checkpoint \
--output_graph=frozen_eval_graph.pb --output_node_names=outputs
- 转换为TensorFlow Lite所需格式的模型
1
2
3
4
5
6
7
8
tflite_convert \
--graph_def_file=frozen_eval_graph.pb \
--output_file=tflite_model.tflite \
--inference_type=QUANTIZED_UINT8 \
--input_arrays=input \
--output_arrays=outputs \
--mean_values=127 \
--std_dev_values=2.0
以MNIST量化训练为例,添加FakeQuant结点后的graph以及转换为tflite格式后的graph见图5所示,点击此处查看TensorFlow MNIST量化训练示例代码。
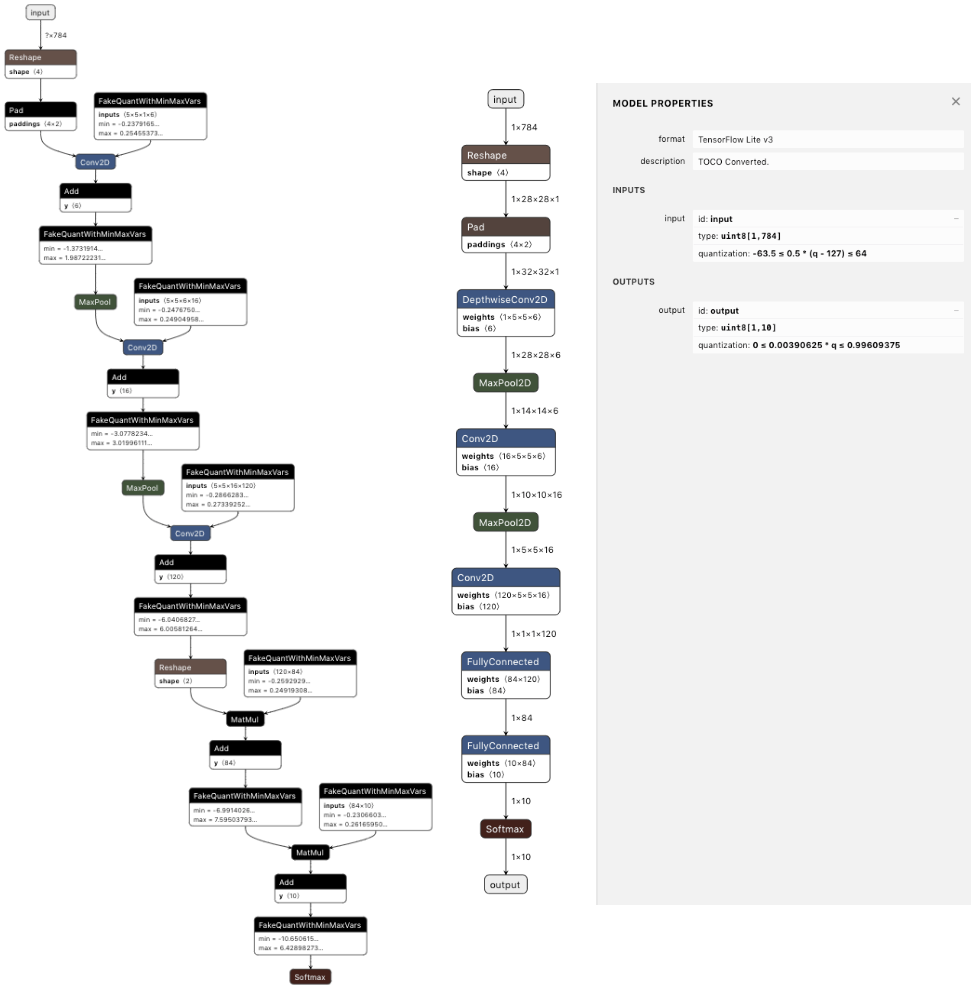
图5 添加FakeQuant结点后的graph(左图)以及转换为tflite格式后的graph(右图)
8. TF量化训练模型精度数据
| Model | Top-1 Accuracy:Floating point3 | Top-1 Accuracy:Fixed point: 8 bit weights and activations |
|---|---|---|
| Mobilenet-v1-224-1 | 0.709 | 0.697 |
| Mobilenet-v2-224-1 | 0.718 | 0.708 |
| Inception_v3 | 0.78 | 0.775 |
参考资料
- Module: tf.contrib.quantize 量化训练tf官网API文档
- TensorFlow quantization-aware training tf官网README
- MobileNet_v1量化训练tf官方教程
- TensorFlow quantization量化训练第三方分析教程
- TensorFlow量化训练步骤及生成量化的tflite(2)
- TensorFlow量化训练全过程
-
Training graph excluding the optimization operation(namely no insertion of gradient ops in a graph) or evaluate graph. ↩