特别声明:未经授权,禁止转载。
本文对XLA源码分析所使用的TensorFlow代码库commit id为d813f80ded2fe1f8aa4e07ead2cb6fc16451b634(master分支), JAX代码库commit id为4dd1f001c626eb15f1a8deac58d97b578a1bd85c(main分支,且使用上述tf对应的commit id)。
1. XLA Pass概述

图 1. XLA Pass 类UML图
分析GpuCompiler::OptimizeHloModule的调用过程,总结在GPU设备上XLA所使用的Pass类型及其之间的关系如图1所示。由图1可知,GPU上所使用的优化Pass基本是HloModulePass和OpExpanderPass的子类。去除四个用于保证HLO到LLVM IR之间转换正确性的Pass,在GPU上XLA使用的优化Pass多达75个。
HloPassInterface位于XLA HLO Pass继承关系的最顶层(即所有Pass类的公共基类),它主要定义了Run和RunOnModuleGroup两个纯虚函数,由其衍生出HloPassPipeline、HloModulePass和HloModuleGroupPass三个子类。XLA HLO Pass优化过程可由多个pipeline构成,每个pipeline即为HloPassPipeline的一个对象。GPU上的XLA Pass优化即被分为spmd-partitioner1、spmd-simplify、optimization、simplification、collective-optimizations、conv-canonicalization、layout-assignment、nvptx post-layout-assignment part 1、post-layout-assignment、nvptx post-layout-assignment part 2、fusion、horizontal-fusion、post-fusion-optimization以及GPU-ir-emit-prepare等14个pipeline,详细功能描述见表1。基本上所有的优化Pass均直接或间接继承自HloModulePass类。OpExpanderPass是HloModulePass的一个子类,由其再派生出十数个子类,主要用于各类算子的展开。HloModuleGroupPass类在XLA中基本没有被使用到。HloPassFix更类似一个修饰类,其模板参数会作为该类的父类,模板参数类被修饰后只会运行固定的迭代次数。
| XLA Pipeline | Pipeline所包含典型XLA优化Pass举例 | 功能描述 |
|---|---|---|
| spmd-partitioner | spmd-simplify/ShardingPropagation/GpuSpmdPartitioner |
数据并行模式中的多GPU划分流水线,划分前会先执行化简流水线 |
| spmd-simplify | ScatterExpander/ GatherExpander/ HloDCE/HloConstantFolding |
数据并行模式下需要额外做的化简操作,其被包含在划分流水线中 |
| optimization | ZeroSizedHloElimination/ CallInliner/DotDecomposer/BFloat16Normalization/BatchNormExpander/DynamicPadder/ simplification |
对计算图中的操作进行优化,包括内联调用、内积分解、BN算子展开以及支持一定程度的动态shape等 |
| simplification | ScatterExpander/ AlgebraicSimplifier/ DotDecomposer/DotMerger/ WhileLoopSimplifier/ ReshapeMover/ HloConstantFolding/ TransposeFolding/ HloCSE/HloDCE |
化简流水线被包含在优化流水线的最后,其主要用于算术操作/Scatter/Dot/Loop/Reshape等操作的化简,并进行常量、transpose等的折叠 |
| collective-optimizations | AllReduceFolder/ReduceScatterCreator/ AllGatherBroadcastReorder |
All-Reduce/All-Gather等集合操作的优化 |
| conv-canonicalization | GpusolverRewriter/ GpuConvRewriter/ CudnnFusedConvRewriter |
将卷积转换为调用cudnn等计算库的CustomCalls,并对其进行规范化(如进行Padding合规添加等)。这里也会展开cuSolver的调用 |
| layout-assignment | FlattenCallGraph/ GpuLayoutAssignment |
基于别名分析对Gpu Layout进行分配,以满足操作数或库调用结果的Layout约束 |
| nvptx post-layout-assignment part 1 | CublasPadForGemms/ HloConstantFolding |
硬件相关的nvptx Layout分配后处理操作第一部分,包括cublas调用padding添加以及常量折叠等优化 |
| post-layout-assignment | ReductionSplitter/ GpuTreeReductionRewriter/ AlgebraicSimplifier/ TransposeFolding/ GemmRewriter/ GemmBroadcastFoldingRewriter/ BFloat16Normalization/ GpuConvAlgorithmPicker/ HloCSE |
Gpu Layout分配的后处理操作,包括使用无原子操作的实现重写reductions、使用cuBLAS GEMM重写Dot/Mul/Add相关操作以及卷积算法选择等。这部分优化是NVPTX和AMD_GPU共享的 |
| nvptx post-layout-assignment part 2 | GemmAlgorithmPicker | 硬件相关的nvptx Layout分配后处理操作的第二部分,主要是对Gemm算法的选择,这部分是nvptx后端独有的 |
| fusion | GpuInstructionFusion/ FusionMerger/ GpuMultiOutputFusion/ HloCSE/HloDCE |
基于HLO指令做融合,包括传统垂直方向上将生产者指令融合到消费者指令中以及融合指令间的合并等 |
| horizontal-fusion | GpuHorizontalLoopFusion/ GpuHorizontalInputFusion/ HloCSE/HloDCE |
水平方向上融合HLO指令,用于降低GPU Kernels Launch开销并增加并行度 |
| post-fusion-optimization | AllGatherCombiner/ AllReduceCombiner/ AlgebraicSimplifier |
融合pipeline的后处理操作,主要用于将较小的集合操作(如AllGather、AllReduce等)进行合并,并执行一些代数化简操作 |
| GPU-ir-emit-prepare | GpuCopyInsertion/ GpuSanitizeConstantNames |
不属于优化Pipeline,仅用于保证生成诸如LLVM IR的正确性 |
2. XLA重点Pass类功能分析
基于TensorFlow 官方ResNet50 benchmark程序resnet50_graph_test,我们在A100-40GB单卡上执行ResNet50的训练过程,以此来分析XLA HLO Pass的优化效果。执行命令中使用了TF_XLA_FLAGS=--tf_xla_auto_jit=2来开启XLA加速。

图 2. ResNet50模型训练中使用到的Pass调用顺序
(黄色块为pipeline,后跟蓝色块为其内部所应用Passes)

图 3. ResNet50模型训练中使用到的Pass及其调用次数
如图2和图3所示,TensorFlow进行ResNet50模型训练并开启XLA时总共触发了72个HLO优化Pass,并且某些Pass的调用次数要大于1,故而Pass调用总次数为97。举例来说,AlgebraicSimplifier的调用次数为5,其在simplification pipeline、collective-optimizations pipeline、post-fusion optimization pipeline、post-layout-assignment pipeline以及conv-canonicalization pipeline等5个pipeline中均被调用一次。图2给出的Pass间连接关系诠释了这些Pass的前后调用依赖。

图 4. TensorFlow + XLA ResNet50模型 A100 单卡 bs256 训练性能
在A100-40GB单卡上执行resnet50_graph_test程序中的benchmark_graph_train部分(batch size = 256),得到的性能数据在830 ~ 910 examples/sec之间浮动(如图4所示),这不利于后续对单个Pass所起效果的分析。再三考虑之后,我们选择使用nsight system工具获取GPU Kernels的总执行耗时以及GPU Kernels执行加显存操作的总耗时来作为性能指标。图5和图6是我们对72个Pass逐一禁用得到的GPU Kernels总执行耗时和GPU上所有操作总耗时的对比分析柱状图。图5和图6中的横坐标是以毫秒为单位的耗时,纵坐标中每一个标签均以DIS_开头,其为Disable的缩写。DIS_None是基线数据,表示不禁用任何Pass, DIS_XX表示禁用某一个Pass。
")
图 5. ResNet50模型训练中使用到的Pass效果分析(batch size=256时的GPU Kernels总执行耗时)
")
图 6. ResNet50模型训练中使用到的Pass效果分析(batch size=256时的GPU操作总耗时)
注意:因禁用GpuConvPaddingLegalization、GpuLayoutAssignment和ReductionDimensionGrouper三个Pass中的任意一个均会导致程序运行出现coredump等严重错误,因此无法测量出禁用这三个Pass时的性能数据。
")
图 7. ResNet50模型训练中使用到的Pass效果分析(高亮关闭后GPU Kernels性能下降1%的Pass)
")
图 8. ResNet50模型训练中使用到的Pass效果分析(高亮关闭后GPU操作总性能下降1%的Pass)
对图5和图6中的数据分别做归一化处理后(除以基线数据耗时),可得到图7和图8。图7和图8中对禁用后性能下降超过1%的Pass做了红色高亮处理。分析图7中的红色高亮部分,可得禁用BatchNormExpander、FusionMerger、GpuConvAlgorithmPicker、GpuInstructionFusion、GpuMultiOutputFusion等5个Pass后,GPU Kernel总执行耗时增加比较明显。分析图8中的红色高亮部分,可得禁用BatchNormExpander、FusionMerger、GpuConvAlgorithmPicker、GpuInstructionFusion、GpuMultiOutputFusion、SortSimplifier等6个Pass后,GPU Kernels执行加显存操作的总耗时增加比较明显。
- GPU Kernels总执行耗时影响程度(性能下降比例):
GpuConvAlgorithmPicker(57%) > GpuInstructionFusion(50%) > BatchNormExpander(20%) > FusionMerger(10%) > GpuMultiOutputFusion(7%) - GPU Kernels执行加显存操作的总耗时影响程度(性能下降比例): GpuConvAlgorithmPicker(52%) > GpuInstructionFusion(47%) > BatchNormExpander(17%) > FusionMerger (6%) > GpuMultiOutputFusion(2%) > SortSimplifier(1%)
因为GPU Kernels执行和显存操作(D2H/H2D/D2D/memset)可能存在并行发生的情况,所以GPU Kernels执行加显存操作的总耗时并不能正确表示训练性能。因此,这里我们主要还是以GPU Kernels总执行耗时作为性能对比指标。根据上述各个XLA HLO Pass对ResNet50模型训练性能的影响程度,下面我们重点分析GpuConvAlgorithmPicker、GpuInstructionFusion、BatchNormExpander、FusionMerger和GpuMultiOutputFusion、AlgebraicSimplifier等六个Pass。
2.1 GpuConvAlgorithmPicker

图 9. GpuConvAlgorithmPicker相关类UML图
GpuConvAlgorithmPicker类主要用于将HLO的CustomCalls修改为cudnn卷积,并为每一个卷积操作选择最佳算法以及为CustomCalls添加显式的暂存空间(scratch space2,即workspace),其定义如图9所示。Run方法是该类的功能入口,其作用对象是HloModule。它基于后序遍历模式对HloModule的每个非融合类型Computation调用私有方法RunOnComputation以处理选定的HloComputation。RunOnComputation方法会遍历其内部的所有Instructions,并对每一条CustomCall卷积指令调用RunOnInstruction方法进行处理。RunOnInstruction方法会调用PickBestAlgorithm方法以便为指定的CustomCall卷积指令选择最佳算法。
xla.proto中定义了message DebugOptions,它是XLA的调试选项,可在任何时刻被改变,但不保证前向和反向中的兼容性。DebugOptions中存在着一些与GpuConvAlgorithmPicker类相关的属性,如xla_gpu_autotune_level和xla_gpu_strict_conv_algorithm_picker等,它们的定义如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
message DebugOptions {
...
// 0: Disable gemm and convolution autotuning.
// 1: Enable autotuning, but disable correctness checking.
// 2: Also set input/output buffers to random numbers during autotuning.
// 3: Also reset input/output buffers to random numbers after autotuning each
// algorithm.
// 4+: Also check for correct outputs and for out-of-bounds reads/writes.
//
// Default: 4.
int32 xla_gpu_autotune_level = 123;
// If true, abort immediately when conv algorithm picker fails, rather than
// logging a warning and proceeding with fallback. Default: True.
bool xla_gpu_strict_conv_algorithm_picker = 156;
// Crashes the program when any kind of verification fails, instead of just
// logging the failures. One example is cross checking of convolution results
// among different algorithms. Default: False.
bool xla_gpu_crash_on_verification_failures = 101;
// An AlgorithmDenylist text proto file as a denylist of convolutions to avoid to use.
string xla_gpu_algorithm_denylist_path = 128;
// Whether to use the cuDNN frontend API for convolutions when possible.
bool xla_gpu_enable_cudnn_frontend = 160;
...
}
xla_gpu_autotune_level控制着gemm和convolution的autotuning过程。其默认值是4,意味着开启gemm和convolution的autotuning过程,并且会检查每次tuning的输出结果正确性以及读写越界与否。设置xla_gpu_autotune_level为0,则关闭gemm和convolution的autotuning过程。可使用XLA_FLAGS=--xla_gpu_autotune_level=0~4设置其值3。- 当
xla_gpu_strict_conv_algorithm_picker设置为True时,在卷积算法选择失败时会立即终止程序而不是仅仅打印一条警告信息并回退继续执行。其默认值为True。可使用XLA_FLAGS=--xla_gpu_strict_conv_algorithm_picker=true/false设置其值。 - 用户可使用
xla_gpu_algorithm_denylist_path设置自定义cuDNN卷积的denylist所处的文件路径。如果用户未设置该路径,则使用XLA默认的kDefaultDenylist(其定义见下文)。AlgorithmDenylist的proto定义详见此链接。 xla_gpu_enable_cudnn_frontend控制是否尽可能地为卷积启用cuDNN frontend API。其设置即使为true也不一定启用cuDNN frontend API,还要求cudnn版本>= 8.1且Layout不为带32元素向量的NCHW_VECT_C(如int8x32)。DebugOptions中各flag的默认值设置详见此链接。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
// kDefaultDenylist的内容
constexpr char kDefaultDenylist[] = R"pb(
entries {
hlo: "(f32[4,32,32,32]{2,1,3,0}, u8[0]{0}) custom-call(f32[4,32,32,32]{2,1,3,0}, f32[5,5,32,32]{1,0,2,3}), window={size=5x5 pad=2_2x2_2}, dim_labels=b01f_01io->b01f, custom_call_target=\"__cudnn$convForward\", backend_config=\"{conv_result_scale:1}\""
cc { major: 7 }
cudnn_version { major: 7 minor: 6 patch: 4 }
algos { id: 7 }
blas_version: "10201"
}
entries {
hlo: "(f32[4,32,32,32]{2,1,3,0}, u8[0]{0}) custom-call(f32[4,32,32,32]{2,1,3,0}, f32[5,5,32,32]{1,0,2,3}), window={size=5x5 pad=2_2x2_2}, dim_labels=b01f_01io->b01f, custom_call_target=\"__cudnn$convForward\", backend_config=\"{conv_result_scale:1}\""
cc { major: 7 }
cudnn_version { major: 7 minor: 6 patch: 4 }
algos { id: 7 tensor_ops: true }
blas_version: "10201"
}
entries {
hlo: "(f16[3,3,256,256]{2,1,0,3}, u8[0]{0}) custom-call(f16[2048,7,7,256]{3,2,1,0}, f16[2048,7,7,256]{3,2,1,0}), window={size=3x3 pad=1_1x1_1}, dim_labels=b01f_01io->b01f, custom_call_target=\"__cudnn$convBackwardFilter\", backend_config=\"{\\\"algorithm\\\":\\\"0\\\",\\\"tensor_ops_enabled\\\":false,\\\"conv_result_scale\\\":1,\\\"activation_mode\\\":\\\"0\\\",\\\"side_input_scale\\\":0}\""
cc { major: 7 }
cudnn_version { major: 8 minor: 2 patch: 1 } algos
[ { id: 0 tensor_ops: true }
, { id: 0 }]
blas_version: "11402"
}
)pb";
卷积算法的选择过程通过GpuConvAlgorithmPicker::PickBestAlgorithm方法完成,该方法存在cache机制,即如果给定指令的卷积算法tune结果(AutotuneResult类型)已经存在,则直接返回tune结果。AutotuneResult定义在autotuning.proto中,展示如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
message AutotuneResult {
enum FailureKind {
UNKNOWN = 0;
// Algorithm wrote memory outside its output buffers.
REDZONE_MODIFIED = 1;
// Algorithm gave a different result from a reference algorithm.
WRONG_RESULT = 2;
// Algorithm was rejected for failing to run or for known bugs.
DISQUALIFIED = 3;
}
message FailureResult {
FailureKind kind = 1;
string msg = 2;
// For failure_kind == WRONG_RESULT, this field indicates the reference
// configuration that we compared against.
//
// Note that the reference algorithm isn't always correct. However,
// empirically it's more correct, as it's "algo 0", less fancy than the
// compared one.
oneof key {
ConvKey reference_conv = 11;
GemmKey reference_gemm = 12;
CudaConvPlanKey reference_cuda_conv_plan = 14;
stream_executor.dnn.AlgorithmProto reference_algorithm = 15;
}
int64 buffer_address = 13;
}
// Legacy and unused in new data; superseded by AlgorithmProto.
message ConvKey {
int64 algorithm = 1;
bool tensor_ops_enabled = 2;
}
message GemmKey {
int64 algorithm = 1;
}
// Legacy and unused in new data; superseded by AlgorithmProto.
message CudaConvPlanKey {
string exec_plan_id = 1;
}
int64 scratch_bytes = 8;
google.protobuf.Duration run_time = 9;
FailureResult failure = 7;
oneof key {
ConvKey conv = 5;
GemmKey gemm = 6;
CudaConvPlanKey cuda_conv_plan = 15;
stream_executor.dnn.AlgorithmProto algorithm = 16;
}
// Next ID: 17
}
PickBestAlgorithm方法中的cache未命中时将根据平台类型调用PickBestAlgorithmNoCacheRocm或者PickBestAlgorithmNoCacheCuda方法,下面我们重点关注PickBestAlgorithmNoCacheCuda方法。其首先调用GetDisabledConvAlgorithms获取当前软硬件环境下需要deny的cuDNN卷积算法,然后调用GetAlgorithms获取当前配置下可使用的cuDNN卷积算法,卷积算法的候选集主要由如下条件决定(Cudnn >= 8.1时,默认使用cuDNN Frontend API):
- FORWARD/BACKWARD_DATA/BACKWARD_FILTER:
- 不使用cuDNN Frontend API
- FORWARD卷积算法候选集:
CUDNN_CONVOLUTION_FWD_ALGO_IMPLICIT_PRECOMP_GEMMCUDNN_CONVOLUTION_FWD_ALGO_IMPLICIT_GEMMCUDNN_CONVOLUTION_FWD_ALGO_GEMMCUDNN_CONVOLUTION_FWD_ALGO_DIRECTCUDNN_CONVOLUTION_FWD_ALGO_FFTCUDNN_CONVOLUTION_FWD_ALGO_WINOGRADCUDNN_CONVOLUTION_FWD_ALGO_FFT_TILINGCUDNN_CONVOLUTION_FWD_ALGO_WINOGRAD_NONFUSED
- BACKWARD_FILTER卷积算法候选集4:
CUDNN_CONVOLUTION_BWD_FILTER_ALGO_1CUDNN_CONVOLUTION_BWD_FILTER_ALGO_FFTCUDNN_CONVOLUTION_BWD_FILTER_ALGO_WINOGRAD_NONFUSEDCUDNN_CONVOLUTION_BWD_FILTER_ALGO_0CUDNN_CONVOLUTION_BWD_FILTER_ALGO_35
- BACKWARD_DATA卷积算法候选集:
CUDNN_CONVOLUTION_BWD_DATA_ALGO_1CUDNN_CONVOLUTION_BWD_DATA_ALGO_FFTCUDNN_CONVOLUTION_BWD_DATA_ALGO_FFT_TILINGCUDNN_CONVOLUTION_BWD_DATA_ALGO_WINOGRADCUDNN_CONVOLUTION_BWD_DATA_ALGO_WINOGRAD_NONFUSEDCUDNN_CONVOLUTION_BWD_DATA_ALGO_06
- FORWARD卷积算法候选集:
- 使用cuDNN Frontend API(要求Cudnn >= 8.1),则根据是否使用fallback决定卷积搜索引擎:
- 不使用fallback,则使用启发式引擎(EngineHeuristicsBuilder)
- 使用fallback,则使用FallbackList引擎(EngineFallbackListBuilder)
- 不使用cuDNN Frontend API
- FORWARD_BIAS_ACTIVATION:
- 不使用cuDNN Frontend API,则所使用的卷积算法候选集与FORWARD类型的相同,支持的激活类型包括
IDENTITY、SIGMOID、RELU、RELU6、RELUX、TANH和BANDPASS,其中IDENTITY激活仅可使用CUDNN_CONVOLUTION_FWD_ALGO_IMPLICIT_PRECOMP_GEMM卷积算法,详见NV文档。 - 使用cuDNN Frontend API(要求Cudnn >= 8.1),亦是根据
use_fallback的值决定使用启发式引擎还是FallbackList引擎。
- 不使用cuDNN Frontend API,则所使用的卷积算法候选集与FORWARD类型的相同,支持的激活类型包括
在使用cuDNN Frontend API时,优先使用启发式引擎选择卷积算法,但如果该方式提供的卷积算法中没有一个可以正常工作的,则会设置
use_fallback=true重新执行GetAlgorithms方法以通过FallbackList引擎选择卷积算法。
确定好卷积算法候选集后,XLA会为该集合中的每个卷积算法创建runner。在去除deny的cuDNN卷积算法后,将实际执行每一个runner,而runner最终会调用cudnnBackendExecute来实际执行卷积计算,并获取计算耗时。最终调用PickBestResult方法,在去除调用失败和出现计算错误的卷积算法后,进一步根据每个卷积算法的计算耗时选择其中最小者作为最佳卷积算法。所选到的最佳卷积算法会在PickBestAlgorithm方法中进行缓存,即将其添加到autotune_cache中。
2.2 BatchNormExpander

图 10. BatchNormExpander相关类UML图
BatchNormExpander用于将batch norm操作改写为多个更细粒度的操作。将大Op打散为更细粒度的小Op有助于后续的通用融合逻辑。
2.3 GpuInstructionFusion

图 11. GpuInstructionFusion相关类UML图
GpuInstructionFusion用于融合HLO指令。传统意义上,指令融合操作是在垂直方向上进行的,这意味将生产者指令融合到其消费者指令中,这样在生成代码时计算它们值的循环将被融合在一起。其重写定义的ShouldFuse方法用于选择可被融合的指令类型。
2.4 FusionMerger

图 12. FusionMerger相关类UML图
FusionMerger是融合指令的合并Pass。如果融合指令的合并结果不会增加字节传输或数据生产者指令可被合并到所有的消费者指令中或数据生产者指令属于Loop型融合指令,则融合指令会被合并。该Pass可降低内存带宽占用并减少kernel launch次数。
1
2
3
4
5
6
7
8
9
10
11
12
Befor merger After meger
p p
| / \
v / \
A +fusion+ +fusion+
/ \ | A' | | A" |
| | | | | | | |
v v | v | | v |
B C | B | | C |
+------+ +------+
2.5 GpuMultiOutputFusion

图 13. GpuMultiOutputFusion相关类UML图
GpuMultiOutputFusion用于GPU后端的同层次兄弟指令以及生产者-消费者指令的多输出融合,以降低内存带宽占用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
0) Before multi- 1) Sibling multi- 2) Producer-consumer
output fusion output fusion multi-output fusion
p p p
| | |
v v v
A A +-fusion--+
/ \ | | A |
| | +-fusion--+ | / \ |
v v | / \ | | B | |
B C | B C | | | | |
\ / | | | | | v v |
v v | v v | | tuple |
ROOT | tuple | +---------+
+---------+ / \
/ \ gte_b gte_a
gte_b gte_c | |
| | | v
\ / | C
v v \ /
ROOT v v
ROOT
2.6 AlgebraicSimplifier
AlgebraicSimplifierl类在若干个优化pipeline中均有使用,它主要提了一些代数化简功能。

图 14. AlgebraicSimplifier相关类UML图
如图14所示,构造AlgebraicSimplifier对象时需要传入一个AlgebraicSimplifierOptions对象,其定义了一系列的代数化简选项,如与layout、dot、conv、scalar multiply reduction、padding及transpose相关选项。AlgebraicSimplifier类重写了父类的Run方法,运行Run方法时会自动创建一个AlgebraicSimplifierVisitor对象visitor,之后使用visitor对HloModule中的每个HloComputation进行处理。每个HloComputation对象会使用传入的AlgebraicSimplifierVisitor对象从Root HloInstruction开始使用后序DFS遍历方式处理该computation中的每一条指令。AlgebraicSimplifierVisitor对象根据每条HloInstruction对象的HloOpcode值调用相应的HandleXXX方法处理该指令。
AlgebraicSimplifierVisitor类会对Abs、Add、And、Bitcast、BitcastConvert、Broadcast、Compare、Concatenate、Constant、Copy、Convert、Complex、Real、Imag、Iota、Convolution、Divide、Dot、Gather、GetTupleElement、Log、Maximum、Minimum、Clamp、Multiply、Negate、Not、Or、Pad、Power、Remainder、Reshape、Reduce、ReduceWindow、Reverse、Rsqrt、Slice、Sqrt、DynamicSlice、DynamicUpdateSlice、Scatter、Select、Sort、Transpose、Subtract和Map等46个算子进行代数化简处理。
HandleAbs:当Abs的操作数为非负时,进行Abs(A) => A的简化。非负判断主要依据Abs操作数的opcode类型:若Abs的操作数来源于如下计算a*a、abs(a)、const值直接与0比较、开根号等,则该操作数一定非负。HandleAdd: 对Add进行的简化操作如下:A + 0 => A0 + A => A- 将常数放在加法的右边,方便后续重分配规则的简化,即
Const + A => A + Const - 对加法的操作数进行重新分配,方便后续的常量折叠,即
(A + C1) + C2 => A + (C1 + C2)
- ……
3. XLA优化Pass对科学计算模型训练性能影响分析
接下来,我们使用科学计算模型(Laplace)分析XLA各个Pass的优化效果,该模型的代码实现详见此处。其中,我们将Dennse层输出节点数512设置为50。使用A100-40GB单卡训练Laplace模型,batch size设为101 * 101(注意:这里一个epoch仅包括一个batch)。在跳过第一个epoch后,累积运行2000个epoch,并通过python的time.time()语句获取总执行耗时以及通过nsight system工具获取GPU Kernels执行耗时。因为分别关闭AlgebraicSimplifier、CallInliner、DotDecomposer、GpuLayoutAssignment、ReductionDimensionGrouper、ReductionLayoutNormalizer或者TransposeFolding等7个Pass之一时均会导致程序执行错误,因此只统计到65个Pass对Laplace模型的训练性能影响程度。
为了确保测量准确性,总执行耗时和GPU Kernels执行耗时相关的实验被重复进行了三次。因为每次得到的结果均类似,所以认为性能实验测量结果是准确的。下文的数据分析是针对其中某一次实验结果进行的。
")
图 15. Laplace模型使用到的Pass效果分析(batch size=101 * 101时的GPU Kernels运行时间)
")
图 16. Laplace模型使用到的Pass效果分析(batch size=101 * 101时的总执行耗时)
图15和图16分别给出了关闭任意一个Pass时Laplace模型GPU Kernels平均总运行时间对比和平均总执行耗时对比。分析图15和图16,可以发现基线(所有Pass全开)总耗时要比基线GPU Kernels总执行时间小。这是因为nsight system虽然可获取GPU Kernels执行信息,但其也会导致总执行耗时增加。因此,GPU Kernels运行时间的测量和总执行耗时的测量是通过两次实验获取的,这难免会导致一些测量误差。
")
图 17. Laplace模型使用到的Pass效果分析(红色高亮关闭后GPU Kernels性能下降5%以上的Pass)
")
图 18. Laplace模型使用到的Pass效果分析(红色高亮关闭后整体性能下降5%以上的Pass)
我们分别使用基线数据对图15和图16进行归一化处理后(baseline / each),得到图17和图18。图17和图18均红色高亮出了对性能影响较大的Pass。
- 分析图17可知,关闭后导致GPU Kernels性能下降5%以上的Pass包括(括号内为关闭后性能下降比例):
GemmRewriter(95.8%) > GpuInstructionFusion(48.9%) > ScatterExpander(20.8%) > GpuTreeReductionRewriter(19.4%) > FusionMerger(14.9%) > GpuMultiOutputFusion(7.9%) - 分析图18可知,关闭后导致整体性能下降5%以上的Pass包括(括号内为关闭后性能下降比例):
GemmRewriter(96.0%) > GpuInstructionFusion(47.6%) > ScatterExpander(25.0%) > GpuTreeReductionRewriter(21.5%) > FusionMerger(16.9%) > DotMerger(15.5%) > GpuMultiOutputFusion(15.0%) > HloCSE(8.8%) > ReductionDegenerateDimRemover(8.2%) > SortSimplifier(6.8%) > RngBitGeneratorExpander(6.1%)
对比图15和图16,可以发现一个有趣的现象,关闭DotMerger Pass后,GPU Kernels的执行时间减少了,但是整体耗时却增加了。这说明DotMerger会带来recompute计算,但是却可以减少IO操作,因此可以带来性能的提升。但是三次实验中也存在一次实验关闭DotMerger后,总执行性能提高了10%左右。计算的增加和IO开销的减少之间是一种折中或者博弈:如果计算的增加带来的性能下降比IO数减少带来的性能提升要高,那么总耗时必然会增加。
虽然图18显示的GpuHorizontalInputFusion关闭后对整体性能影响不大,但三次实验中存在一次关闭GpuHorizontalInputFusion后,整体性能下降了11%左右。因此该Pass可能也需要多关注一些。
因为使用python的time.time()测量总体耗时可能存在一些误差,因此我们在此优先关注整体性能影响在10%以上的Pass。结合对GPU Kernels性能影响显著的Pass,可得出在Laplace模型上需要重点关注如下8个Pass的功能:
- GemmRewriter
- GpuInstructionFusion
- GpuMultiOutputFusion
- GpuHorizontalInputFusion
- FusionMerger
- ScatterExpander
- GpuTreeReductionRewriter
- DotMerger
在第二小节中,我们已经分析过GpuInstructionFusion、GpuMultiOutputFusion以及FusionMerger等Pass的功能,接下来将主要分析DotDecomposer、DotMerger、GemmRewriter、ScatterExpander、GpuScatterExpander、WhileLoopConstantSinking、WhileLoopSimplifier、GpuTreeReductionRewriter和GpuHorizontalInputFusion的功能。
3.1 DotDecomposer
3.1.1 收缩维度和非收缩维度

图 19. 关于收缩维度和非收缩维度的解释
举例:
- \(m * k \times k * n\)中,k属于收缩维度, m和n均属于非收缩维度
- \(b * m * k\),b -> 2, m -> 1, k -> 0,则
minor_to_major = [2, 1, 0]为行优先存储方式
3.1.2 非标准Dot的定义
- 若dot的收缩维度大小多于1个,则该dot是非标准的。
- 若dot拥有多于1个的非收缩维度,则该dot是非标准的。非标准形式符合如下条件:
dot.lhs_batch_dimensions_size() + 2 < instruction->operand(0)->shape().rank() || dot.rhs_batch_dimensions_size() + 2 < instruction->operand(1)->shape().rank()(Tips: \(b * m * k \times k * n\))dot.lhs_batch_dimensions().empty() && dot.lhs_contracting_dimensions().empty()
- 检查batch dims是否存在:若存在,则标准Dot形式的batch dims应为
[0, 1, ..]或者为空([])
3.1.3 标准Dot的定义
DotDecomposer Pass用于将所有dot转换为标准形式,且标准形式的定义如下:
- 将非收缩维度7reshape到一起
- 将收缩维度reshape到一起
- batch维度作为最外层维度(
the most major dim)
3.1.4 标准Dot转换流程
DotDecomposer Pass在转换非标准dot时,具体执行如下操作:
- 使用
transpose指令将左操作数调换为[batch_dims, non_contracting_dims, contracting_dims]。 - 使用
reshape指令将左操作数重塑为[batch_dims, product of non_contracting_dims, product of contracting_dims。 - 使用
transpose指令将右操作数调换为[batch_dims, contracting_dims, non_contracting_dims]。 - 使用
reshape指令将右操作数重塑为[batch_dims, product of contracting_dims, product of non_contracting_dims。 - 使用输出维度
[batch_dims, product of lhs_non_contracting_dims, product of rhs_non_contracting_dims]创建一个新的dot指令。 - 对新的dot指令输出进行reshape操作,变换得到原始dot输出的shape。
3.1.5 DotDecomposer变换示例
| 非标准Dot(变换前) | 标准Dot(变换后) |
|---|---|
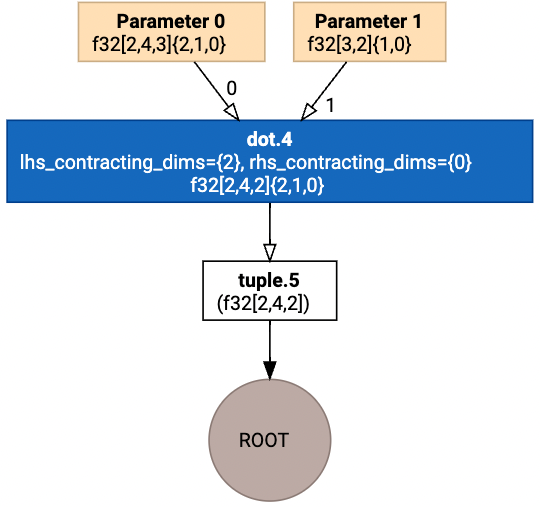 |
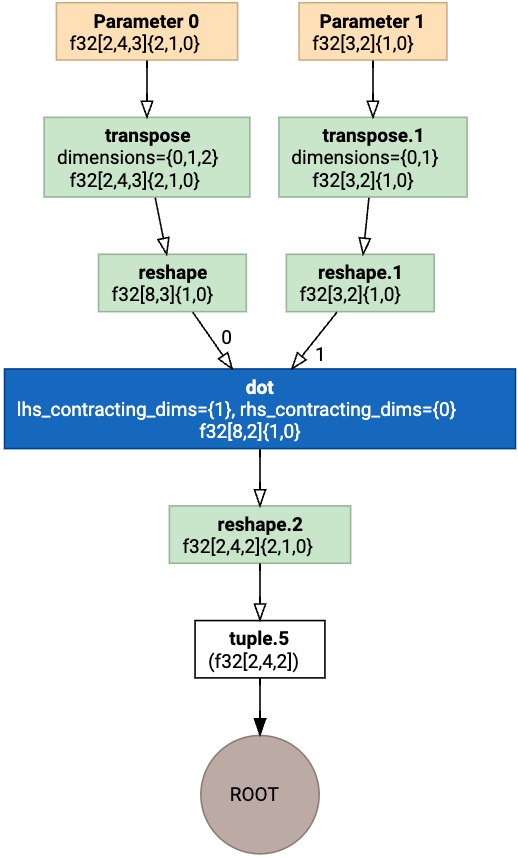 |
3.2 DotMerger
DotMerger Pass所执行的变换如图19所示,可进行此类变换的提前是X和Y必须是相互独立的,即X不传递依赖Y且Y也不传递依赖X。当合并的Dot操作比原始的多个Dots操作要快时,执行此类变化是有益的。当然,我们也应该意识到合并计算Dot的结果Z的生命周期等于原来X和Y的生命周期较大者,这可能会导致显存占用比之前要高。因此,我们更希望合并的是那些较小的Dot操作。XLA允许后端设置一个最大尺寸,超过该尺寸的Dot将不会合并。具体来说,至少有一个输入+输出总字节数要小于所设置的阈值,否则将不会合并两个Dots。这里并不需要两个Dots的尺寸都在阈值以下,毕竟将小的Dot合并到大的Dot中是有意义的。
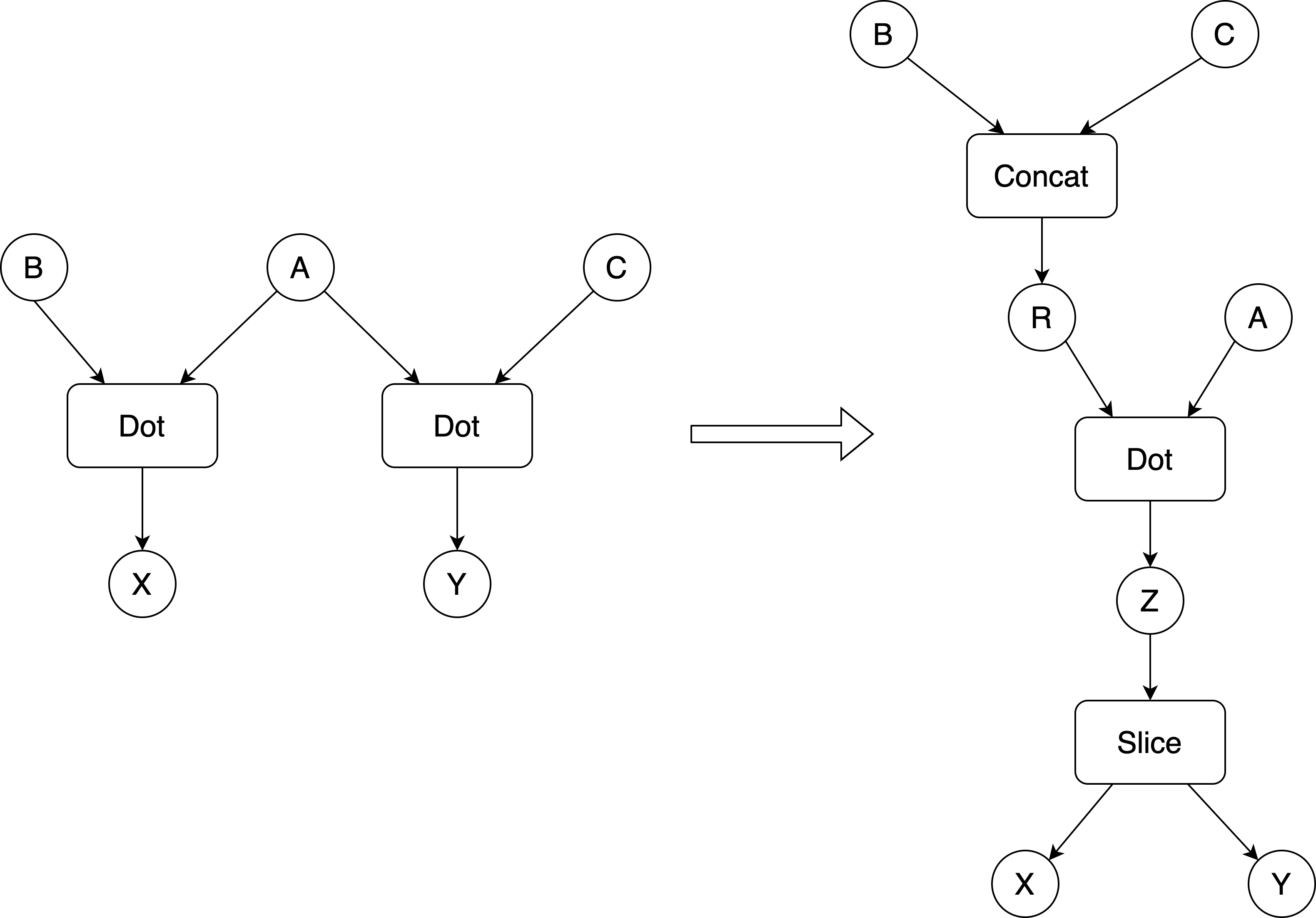
图 20. DotMerger Pass所执行变换示意图
注意:进行DotMerger前需要先执行DotDecomposer Pass,以保证所有Dot已被规范化。该Pass会跳过非规范化的Dot操作。
3.3 GemmRewriter
cuBLAS GEMM的通用形式可使用Add(Multiply(Dot(A, B), alpha), Multiply(C, beta))(即\(\alpha \odot (A \cdot B) + \beta \odot C\))操作组合进行表达。其中A、B、C均为矩阵,alpha和beta是host端的常量。
- 进行上述表达GEMM融合的条件:C不被其他指令所使用,否则将其融合到一个custom call中是不可行的。
- alpha设置为1利用避免乘法,beta设置为0可以避免加法。
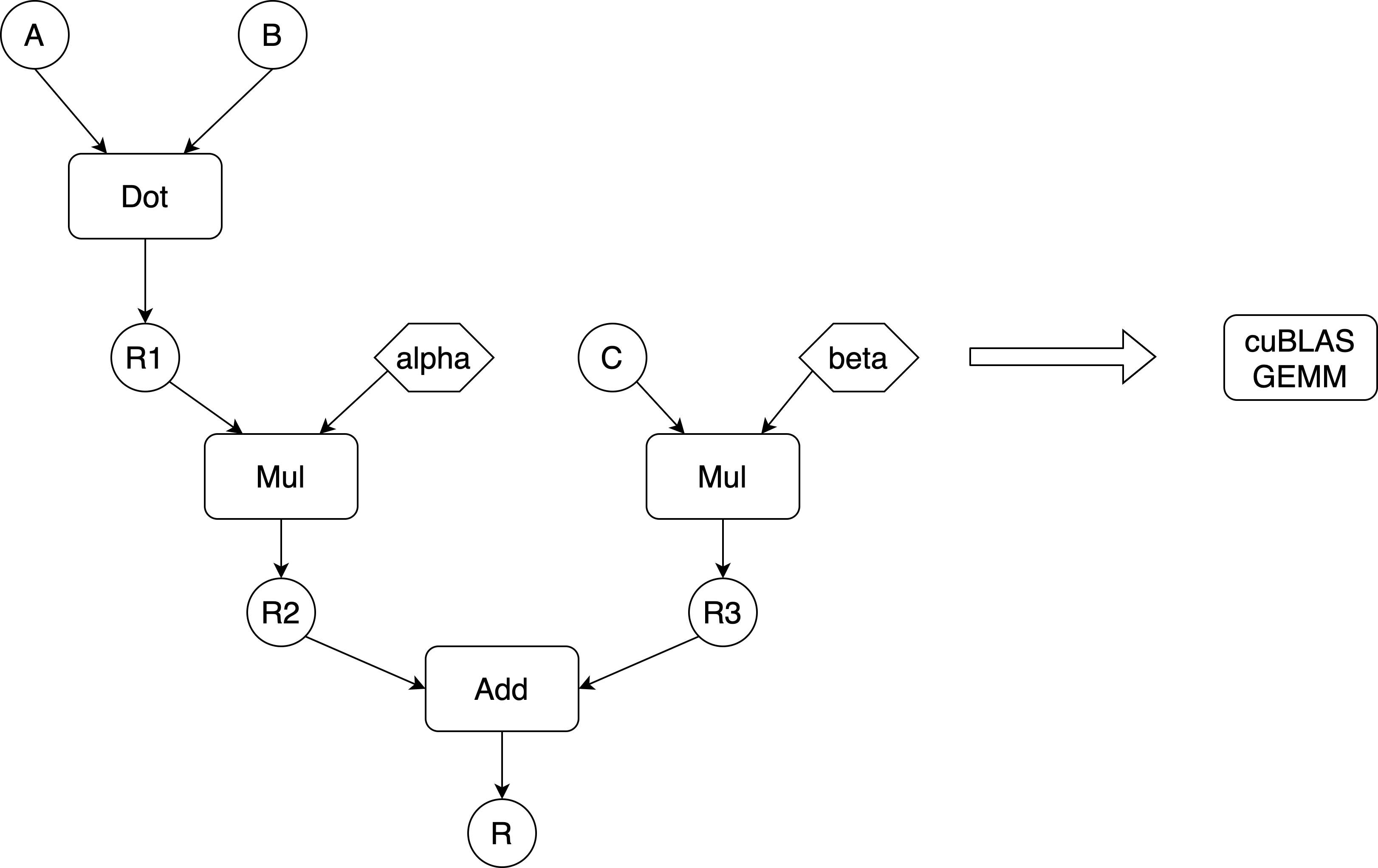
图 21. GemmRewriter Pass所执行变换示意图
在执行GemmRewriter Pass前会先执行TransposeFolding Pass,该Pass会将transpose操作折叠到Dot操作中,而Dot操作一般会被实现为一个可对其输入进行转秩的GEMM kernel。在完成transpose折叠后,GemmRewriter Pass将上述最通用的操作模式重写为一个custom call,其中A、B、C分别为其三个操作数,而alpha和beta则被存储在backend配置中。
3.4 ScatterExpander
ScatterExpander Pass将scatter算子展开为一个由动态slice + update(add/sub/mul/div)组成的while循环。传统MPI语义中,scatter给每个进程发送的是一个数组的一部分数据8,如图22所示。
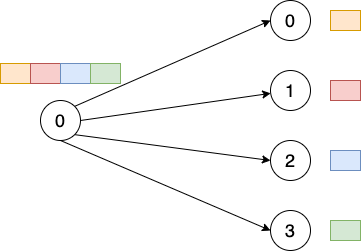
图 22. Scatter语义示意图
下面以scatter_add为例阐述XLA中的scatter算子行为,其输入包括ref[r0, r1, r2, r3, r4, r5]、indices[2, 0, 5]和updates[u0, u1, u2]。执行完scatter_add操作后,ref的值被更新为[r0+u1, r1, r2+u0, r3, r4, r5+u2]。
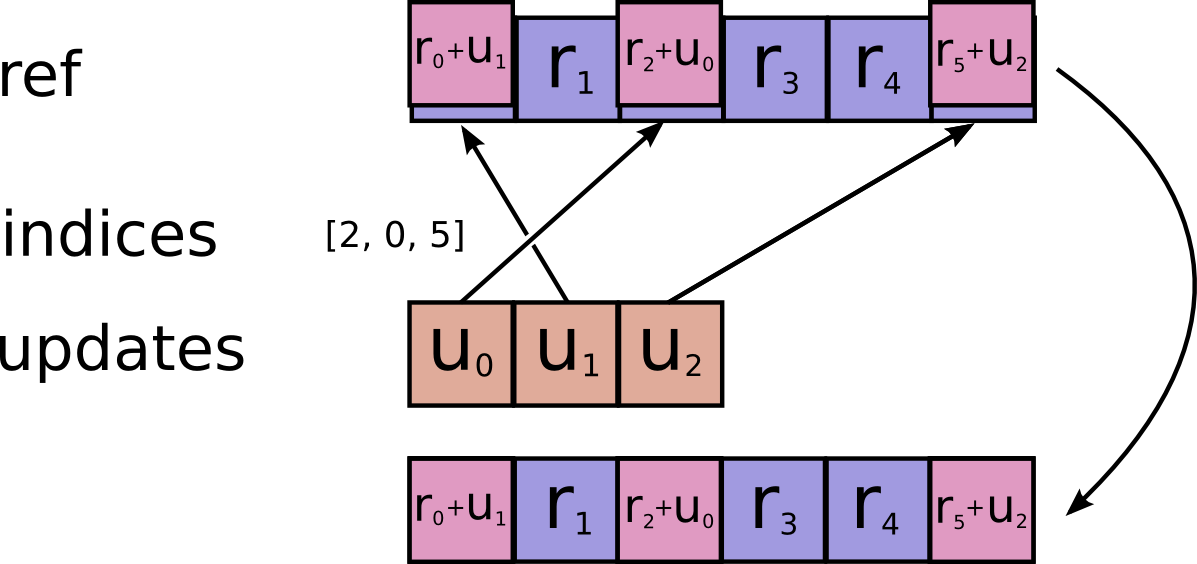
图 23. XLA Scatter Add语义示意图
ScatterExpander Pass对scatter的展开操作支持两种模式:
kEliminateAllScatters:若后端不支持scatter操作语义,则将每个scatter算子都完全展开为一个while循环。kEliminateSimpleScatters:若后端支持scatter操作语义,则只将小的scatter算子(indices维度为1,即indices数组仅包含一个元素)展开为迭代数为1的while循环,且该循环会在后续的WhileLoopSimplifierPass中被消除。经过一系列操作后,小的scatter算子在HloModule中便不复存在。
将scatter算子全展开为一个while循环的具体步骤描述如下:
- 获取数组
indices的第n个索引值In - 获取Tensor
updates的第n个切片Un - 根据索引值In获取待更新Tensor
ref的第In个切片Rn - 执行计算过程:
Rn += Un/Rn -= Un/Rn *= Un/Rn /= Un/ …
3.5 GpuScatterExpander
和ScatterExpander的唯一区别在于展开条件的设置不同:
ScatterExpander的展开条件:inst->opcode() == HloOpcode::kScatter && (mode_ == kEliminateAllScatters || ScatterTripCount(inst) == 1),即使用kEliminateAllScatters模式或者只展开简单的小scatter算子。GpuScatterExpander的展开条件:inst->opcode() == HloOpcode::kScatter && primitive_util::BitWidth(inst->shape().element_type()) > 64,即元素类型的位宽大于64 bit时才进行展开。
注意XLA Pass调用中是先执行的GpuScatterExpander Pass再执行的ScatterExpander Pass。
3.6 WhileLoopConstantSinking
WhileLoopConstantSinking主要用于将while循环体中实际为常量的变量替换为其相应的常量值。举例如下:

图 24. WhileLoopConstantSinking常量转换示意图
仔细观察图24可知,常量替换后,循环里仍遗留着未使用的v,其会在后面的WhileLoopSimplifier Pass中消除。
另外,多层循环中的常量值也能被逐层替换,举例如下:
1
2
3
4
5
6
7
8
9
10
11
state = (..., const_v, ...)
while (pred(state)) {
(..., v, ...) = state
...
inner_state = (..., v, ...)
while(pred(inner_state)) {
(..., inner_v, ...) = inner_state
use(inner_v) // 内层循环里的inner_v也会被逐层替换为const_v
}
state = (..., v, ...)
}
3.7 WhileLoopSimplifier
WhileLoopSimplifier Pass主要根据如下规则对whle循环进行化简:
- 若循环迭代次数为0,则直接删除该循环
- 若循环迭代次数为1,则使用循环体替换该循环,此处即将前述的小
scatter算子消除掉 - 移除循环中未使用的变量,此处即将前述遗留的变量
v消除掉 - 移除while循环初始传入的多个tuple语句中的重复变量,示例如下
1 2 3 4 5 6
state1 = (a, b, ...); state2 =(a, c, ...); // 此处a是重复的 while(pred(state1)) { (x, y, ...) = state1 (i, j, ...) = state2 // 虽然此处解包时变量名改变了,但是实际x和i是同一变量,因此可被消除 }
x和i是重复的,它们都指向同一个变量a,因此可以消除i - 若while循环中使用的是一个嵌套tuple(如
tuple(a, tuple(b, c))),则将该tuple展开为非嵌套类型(即tuple(a, b, c)),这样可以减少kTuple指令的数目- 嵌套tuple被展开后,可能会增加一些while循环中未使用的tuple元素(例如,解包后的变量
b可能在循环中并未被使用)。庆幸的是,这些变量在后续的Pass中也会被优化掉。
- 嵌套tuple被展开后,可能会增加一些while循环中未使用的tuple元素(例如,解包后的变量
3.8 GpuTreeReductionRewriter
GpuTreeReductionRewriter Pass基于预设的规则将一个HLO Reduce指令重写为2个HLO Reduce指令,以增加其并行度同时避免原子操作。
GpuTreeReductionRewriter Pass首先通过GetReductionTiling辅助函数获取Reduce Kernel实现中的tile大小,其计算规则描述如下:
- 若为row reduction,则\(tile = \{min(reduce\_dim[0], 8), 1, 16\}\)
- 若为column reduction,则\(tile = \{1, 128, 1\}\)
GpuTreeReductionRewriter Pass主要根据tile大小按如下规则对Reduce进行重写:
- 若为row reduction,且
batched dimension已知 && 其大于tile[0]的值((即shape[0] > tile[0])),则按每个reduce维度一一展开,举例如下
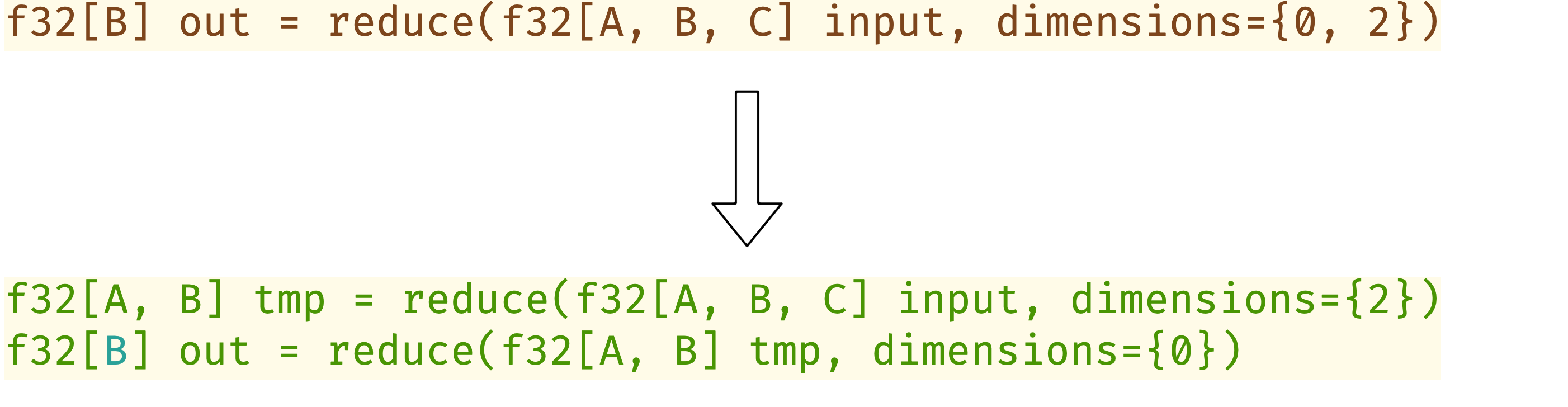
图 25. row reduction展开示意图
- 若无冲突则无需展开,这包括两种情况:
- 若为row reduction,则要求\(reduce\_dim[2] \le 1024 * tile[2]\)
&&\(reduce\_dim[0] \le 8\) - 若为column reduction,则要求\(reduce\_dim[1] \le 32 * tile[1]\)
- 若为row reduction,则要求\(reduce\_dim[2] \le 1024 * tile[2]\)
-
若为其它情况,则取待reduce的最后一维大小,然后计算其根平方值,并将待reduce的维度padding到该值的整数倍,伪代码描述如下:
\[\begin{array}{**l**} n = shape[reduce\_dim[-1]] \\ num\_fit = (\lceil \sqrt{n} \rceil)^2 \end{array}\]- 若为row reduction,则对输入为
f32[B] out = reduce(f32[A, B, C] input, dimensions={0, 2})的reduce操作进行如下重写:1 2 3 4 5
// Let M = num_fit f32[A, B, P] padded = pad(input) // Let P = ceil(C/M) * M. f32[A, B, Q, M] reshaped = bitcast(padded) // Let Q = ceil(C/M) f32[B, Q] inner_reduce = reduce(reshaped, dimensions={0, 3}) f32[B] outer_reduce = reduce(inner_reduce, dimensions={1})
- 若为column reduction,则对输入为
f32[A, C] out = reduce(f32[A, B, C] input, dimensions={1})的reduce操作进行如下重写:1 2 3 4 5
// Let T = num_fit f32[A, P, C] padded = pad(input) // Let P = ceil(B/T) * T. f32[A, Q, T, C] reshaped = bitcast(padded) // Let Q = ceil(B/T) f32[A, Q, C] inner_reduce = reduce(reshaped, dimensions={2}) f32[A, C] outer_reduce = reduce(inner_reduce, dimensions={1})
- 若为row reduction,则对输入为
3.9 GpuHorizontalInputFusion
GpuHorizontalInputFusion Pass水平地融合kInput类型的融合指令,主要用于降低GPU上的kernel launch开销并增加并行度。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
i0 i1 i2 i3 i0 i1 i2 i3 +++ (Slice) Input Fusion
| | | | | | | | +
v v v v v v v v +
Mul Add ===> Mul Add +
| | | | +
v v v v +
(ROOT) tuple Reshape0 Reshape1 +
| | +
v v +
Concatenate +
| | +
v v +
Slice0 Slice1 +++
| |
v v
Reshape2 Reshape3
| |
v v
(ROOT) tuple
4. TensorFlow的LOG打印控制
TensorFlow使用了类似GLOG的打印接口,如LOG(INFO)、VLOG(1)等,但是其并没有引入GLOG库,而是在tensorflow/core/platform/default/logging.h文件中实现了一套类似的打印机制。TF_CPP_LOG功能中与LOG和VLOG打印控制相关的环境变量解释如下:
- TF_CPP_MIN_LOG_LEVEL:控制LOG语句的打印,不设置相当于
TF_CPP_MIN_LOG_LEVEL=0。举例:TF_CPP_MIN_LOG_LEVEL=1。- INFO = 0
- WARNING = 1
- ERROR = 2
- FATAL = 3
- NUM_SEVERITIES = 4
- TF_CPP_MAX_VLOG_LEVEL:控制VLOG语句的打印,类似于
GLOG_v的功能,不设置相当于TF_CPP_MAX_VLOG_LEVEL=0。举例:TF_CPP_MAX_VLOG_LEVEL=4。 - TF_CPP_VMODULE:控制只打印匹配到文件中符合条件的VLOG语句,类似于
GLOG_vmodule功能。举例:TF_CPP_VMODULE=gpu_compiler=5。 - TF_CPP_VLOG_FILENAME:若设置了环境变量
TF_CPP_VLOG_FILENAME, 则所有的LOG和VLOG打印信息都会重定向到TF_CPP_VLOG_FILENAME指定的文件中。举例:TF_CPP_VLOG_FILENAME=tf_log.txt。 - TF_CPP_LOG_THREAD_ID:若
TF_CPP_LOG_THREAD_ID被设置为一个不为0的值,则所有的LOG和VLOG打印信息中均会带上thread id的值(默认不打印)。举例:TF_CPP_LOG_THREAD_ID=1。
JAX中不能打印
LOG(INFO)的输出信息原因分析:jax/__init__.py文件中使用os.environ.setdefault('TF_CPP_MIN_LOG_LEVEL', '1')语句关闭了LOG(INFO)的打印信息,即只有\(\ge\) WARNING的LOG信息才能打印。
5. 附录
表2给出了TensorFlow + XLA和Paddle + CINN在ResNet50模型上的A100单卡训练性能数据。
实验配置:A100-40GB单卡,batch size = 256
| Framework | GPU Kernel Time (ms) |
GPU Kernel+Mem Time (ms) |
Speed (images/sec) |
|---|---|---|---|
| TensorFlow + XLA | 257 | 290~310 | 830 ~ 910 |
| Paddle + CINN | 296 | 310 | 862 |
-
SPMD (Single-Program-Multiple-Data) 是最常用的分布式模式,即数据并行。 ↩
-
In general, a scratch space is a temporary location in memory that allows for something to be saved. ↩
-
使用XLA_FLAGS同时设置多个flag值的方法:
XLA_FLAGS="--xla_gpu_strict_conv_algorithm_picker=false --xla_gpu_autotune_level=0"。 ↩ -
XLA代码注释中解释
CUDNN_CONVOLUTION_BWD_FILTER_ALGO_WINOGRAD在cudnn.h没有实现,而CUDNN_CONVOLUTION_BWD_FILTER_ALGO_FFT_TILING在某些shape下会产生错误的结果,所有这两个算法不在搜索列表中。 ↩ -
CUDNN_CONVOLUTION_BWD_FILTER_ALGO_0和CUDNN_CONVOLUTION_BWD_FILTER_ALGO_3会导致每次计算结果为非确定的。 ↩ -
CUDNN_CONVOLUTION_BWD_DATA_ALGO_0会导致每次计算结果为非确定的。 ↩ -
On the Performance Prediction of BLAS-based Tensor Contractions ↩