特别声明:未经授权,禁止转载。
本文源码分析所使用的代码库信息如下:
- TensorFlow代码库commit id为0d5668cbdc6b46d099bd3abd93374c09b2e8121f(master分支)
- JAX代码库commit id为af89426a73664b6c58c2a933c0dde0aded8c9391(main分支,且使用上述tf对应的commit id)
- torch-mlir代码库commit id为636f5acb103283522193f8673f411808ec475b95(main分支)
背景介绍
当前,神经网络编译器诸如XLA、TVM、Glow以及多面体编译器AKG等,均是在自身内部构建了独有的高层次IR,并在其上执行各种transformation优化,最终再将这些优化后的高层次IR递降到LLVM IR以生成二进制文件。这样就很难将A编译器中做得好的优化部分迁移到B编译器中,不利于代码模块化和可重用化。另一个问题是,在跨越面向用户的抽象以及用于执行分析和转换的编译器IR层级之间gap时过快,这导致如下两个问题:
- 丢失在更高级别IR上的可用信息。
- 从低层IR重建高级语义信息会导致优化流程更加混乱。
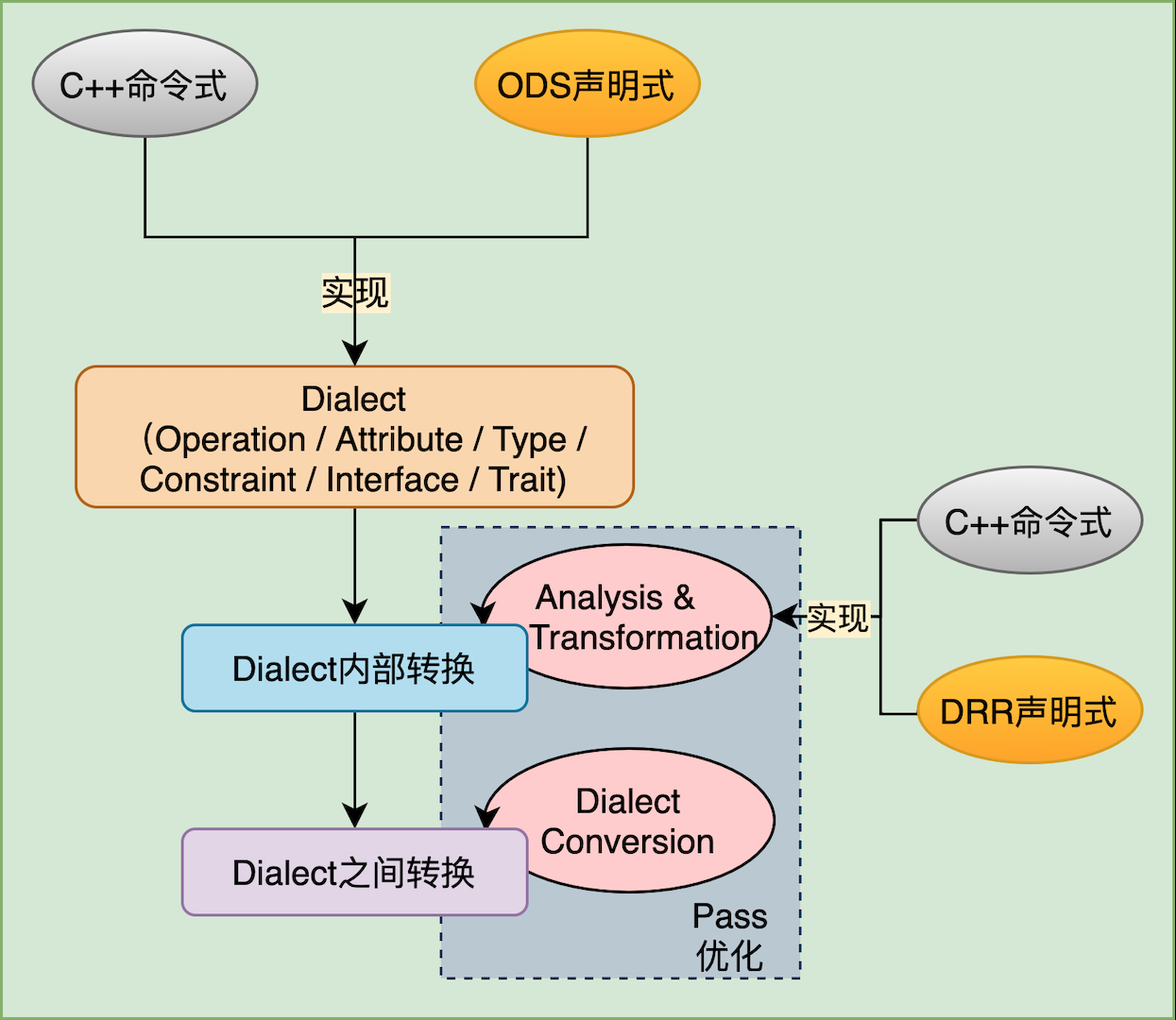
MLIR1是一种新的编译器基础设施,它大大降低了定义和引入新的抽象级别以构建特定领域IR的入门成本。它是LLVM项目的一部分,设计理念源于数十年编译器构建的实践。MLIR的核心目的在于弥补框架和底层硬件之间的gap,以递降方式连通上层框架和下层硬件,解决工具主要是Dialect和DialectConversion两把”利刃”,具体实现方案如下图所示:
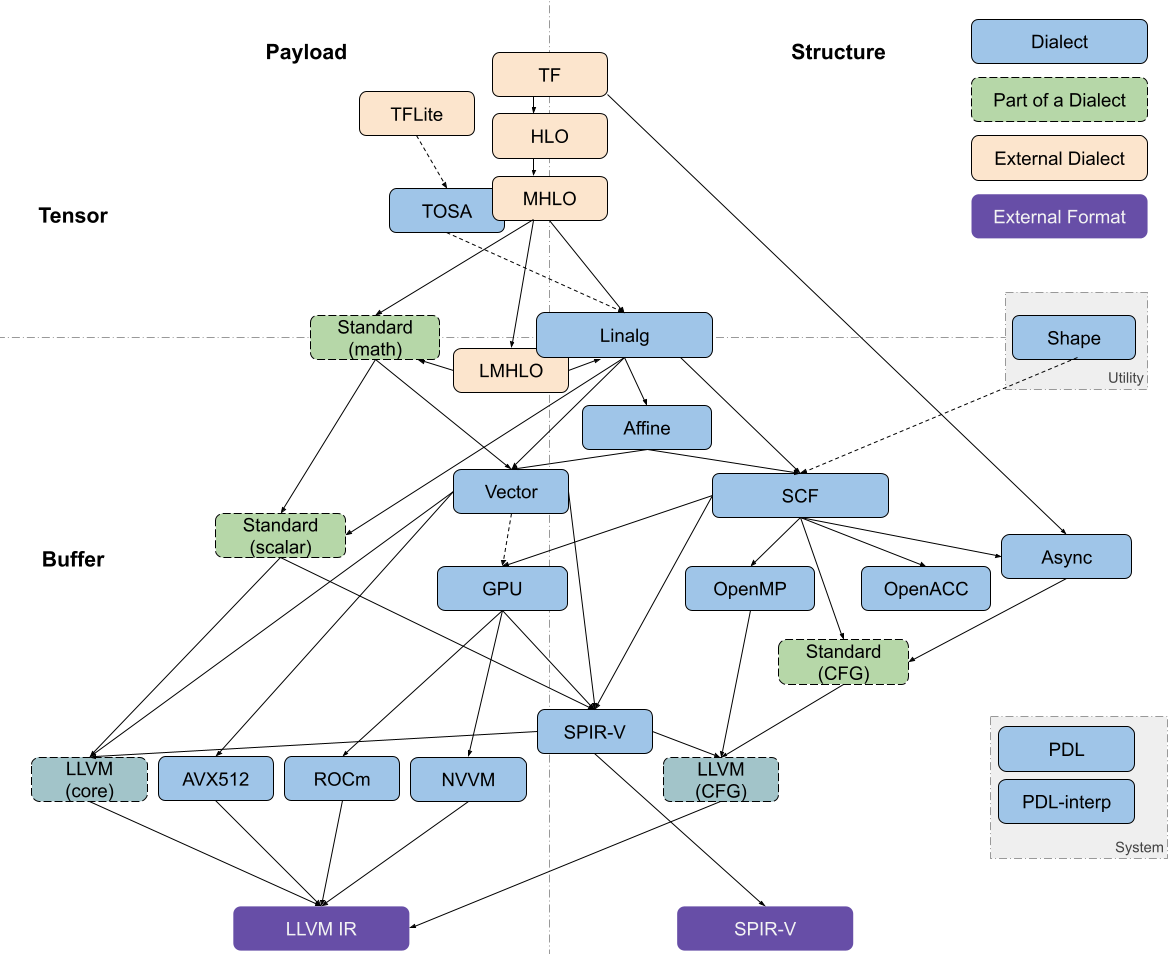
MLIR中与代码生成相关的Dialect可以大致沿两个维度进行划分:Tensor <–> Bufffer以及 Payload(负载操作,主要是计算密集型操作) <–> Structure(结构化操作,如控制流等)。常见的Dialects所属区域如图2所示2。
MLIR in TensorFlow
TensorFlow中使用的神经网络编译器为XLA,其主要通过MarkForCompilationPass、EncapsulateSubgraphsPass、BuildXlaOpsPass等将用户构造的计算图替换为XlaCompileOp和XlaRunOp,详细流程如下图所示:
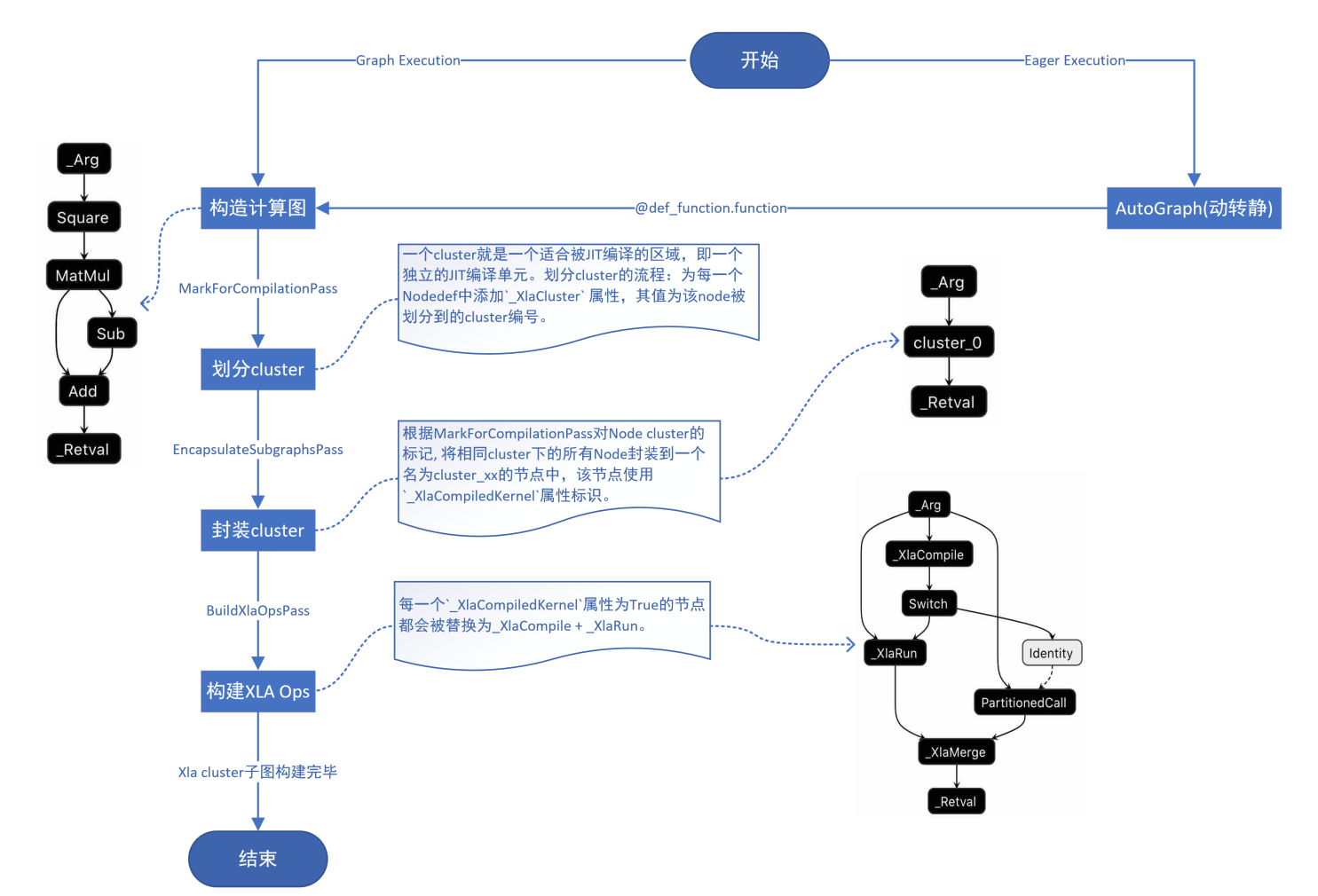
XlaCompileOp和XlaRunOp的流程
在启动运行后,执行到XlaCompileOp时会调用tensorflow::XlaCompiler::CompileFunction对计算子图进行编译。若在启动时设置了TF_XLA_FLAGS="--tf_mlir_enable_mlir_bridge=true --tf_mlir_bridge_safe_mode=false"环境变量,则CompileFunction会调用tensorflow::CompileGraphToXlaHlo函数,该函数会进一步调用tensorflow::ConvertGraphToMlir函数将tensorflow::Graph转换为mlir::ModuleOp。转换涉及的MLIR Dialect列举如下:
- mlir::TF::TensorFlowDialect
mlir::tf_type::TFTypeDialect- ` mlir::tf_device::TensorFlowDeviceDialect`
mlir::tf_executor::TensorFlowExecutorDialectmlir::tf_saved_model::TensorFlowSavedModelDialectmlir::tfg::TFGraphDialectmlir::arith::ArithmeticDialectmlir::func::FuncDialectmlir::cf::ControlFlowDialect
此时,便进入了MLIR领域,当前TensorFlow会通过调用tensorflow::CompileGraphSetup函数在mlir::ModuleOp上进行如下Pass优化(详见mlir::TF::CreateTFStandardPipeline):
- 移除死代码(GraphPruningPass)
- 尽可能多地融合孤岛指令(ExecutorIslandCoarseningPass)
- 内联(MaterializePassthroughOpPass)
- ClusterFormationPass
- mlir::createCanonicalizerPass
- mlir::TF::ShapeInference
- mlir::createInlinerPass
- mlir::createSymbolDCEPass
- TensorFlowOptimizePass
- mlir::createCSEPass
tf中xla开启MLIR相关的Flags:TF_XLA_FLAGS=”–tf_mlir_enable_mlir_bridge=true –tf_mlir_bridge_safe_mode=false –tf_mlir_enable_merge_control_flow_pass=true –tf_mlir_enable_convert_control_to_data_outputs_pass=false”
优化后的MLIR module会被tensorflow::CompileMlirToXlaHlo函数转换为存储在XlaComputation中的XLA HLO module。期间,CompileMlirToXlaHlo内部会调用tensorflow::ConvertMLIRToXlaComputation,进而调用tensorflow::LegalizeToHlo函数将mlir::TF::TensorFlowDialect等转换为mlir::mhlo::MhloDialect(可参考tensorflow::CreateConvertMlirToXlaHloPipeline、mlir::mhlo::createLegalizeTFPass和LegalizeTF),最后mlir::ConvertMlirHloToHlo函数会将MHLO Dialect转换为XLA HLO proto(xla::HloProto),由XLA HLO proto构建而来的XLA HLO module会被存储在XlaComputation中。
之后的步骤和不使用MLIR时相同,即通过tensorflow::XlaCompilationCache::BuildExecutable调用将XlaComputation编译成可执行文件。期间,BuildExecutable会调用xla::gpu::GpuCompiler::RunHloPasses对HloModule进行优化,而优化后的HloModule又会被xla::gpu::CompileModuleToLlvmIrImpl函数转为MLIR module(内部调用mlir::HloToLhloModule完成向mlir::lmhlo::LmhloDialect的转换),接着调用xla::gpu::IrEmitterUnnested会将MLIR Module递降到LLVM module,最后xla::gpu::GpuCompiler::CompileToTargetBinary函数会将LLVM module编译成二进制文件。
MLIR in Jax

Jax可以对python函数使用@jit进行装饰,装饰后对原函数的调用即转变为对jax::(anonymous namespace)::CompiledFunction::Call的调用,具体转换流程详见图4。Laplace2D模型中使用jax.jit进行装饰的示例代码如下:
1
2
3
4
5
6
7
8
from jax import jit
@jit
def update(i, opt_state, inputs):
params = get_params(opt_state)
total_loss = loss(params, inputs)
opt_state = opt_update(i, grad(loss)(params, inputs), opt_state)
return total_loss, opt_state

如图5所示,首次调用CompiledFunction::Call方法cache未命中时,jax会先将python函数转换为Jaxpr对象,再转换为mlir.Module对象。最后基于mlir.Module对象进行编译即得到可执行文件,编译流程详见图6(对应图5中的第15步)。

_xla_callable_uncached编译mlir.Module得到可执行文件的流程
图6中的MlirToXlaComputation函数在将mlir::ModuleOp转换为XlaComputation前会对mlir::ModuleOp进行如下Pass优化:
- ChloLegalizeToHloPass:将
mlir::chlo::HloClientDialect转换为mlir::mhlo::MhloDialect,用于合法化broadcast操作以及将一些组合操作进行分解。lower_jaxpr_to_module对jaxpr进行转换时,调用的jaxpr_subcomp函数会依据lowering规则(使用mlir.register_lowering注册得到)将jaxpr lowering为chlo和mhlo两个dialect的混合表示形式。虽然其中绝大部分lowering规则使用的是mhlo,但是存在chlo.NextAfterOp、chlo.LgammaOp、chlo.DigammaOp这三个chlo Op的使用。 - mlir::createCanonicalizerPass
- SinkConstantsToControlFlowPass:A pass that sinks constants implicitly captured in control flow regions. This is necessary to export to XLA.
MLIR in Torch-MLIR
Torch-MLIR主要通过设计一套TorchDialect,将PyTorch模型引入到MLIR领域。通过lib/Conversion目录下设计的各种转换pattern和pass,可进一步将TorchDialect转换为Linalg、Tosa、Mhlo等MLIR Dialects。后续硬件vendor可基于Linalg/Tosa/Mhlo等设计自己的后端执行方式,Torch-MLIR提供的RefBackendLinalgOnTensorsBackend等运行时默认使用的是CPU。Torch-MLIR主要服务于新硬件厂商,他们只需要将自己的精力集中在对接Linalg/Tosa/Mhlo等MLIR Dialects上,而无需考虑繁多的上层深度学习框架(如TensorFlow/PyTorch等)。
使用torch-mlir进行jit执行计算过程的代码示例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
import torch
import torch_mlir
from torch_mlir_e2e_test.linalg_on_tensors_backends.refbackend import RefBackendLinalgOnTensorsBackend
def compile_and_load_on_refbackend(module):
# RefBackendLinalgOnTensorsBackend是LinalgOnTensorsBackend的一个子类
backend = RefBackendLinalgOnTensorsBackend()
# compile方法内部调用run_pipeline_with_repro_report(imported_module, LOWERING_PIPELINE, ...)
# 函数将使用Linalg-on-Tensors Dialcet表示的module递降为使用LLVM Dialect表示的module
compiled = backend.compile(module)
# load方法返回RefBackendInvoker类型对象,该对象内部会使用LLVM Dialect表示的module作为参数创建一个ExecutionEngine对象
# 备注:python端ExecutionEngine类继承自pybind11封装的_mlirExecutionEngine.ExecutionEngine类
return backend.load(compiled)
# 创建示例torch模型
class TanhModule(torch.nn.Module):
def forward(self, a):
return torch.tanh(a)
# 将torch模型递降到linalg-on-tensors形式
compiled = torch_mlir.compile(TanhModule(), torch.ones(3), output_type=torch_mlir.OutputType.LINALG_ON_TENSORS)
# 将MLIR module编译为可执行module,待编译的MLIR module应只包含使用Linalg-on-Tensors和Scalar表示的代码
jit_module = compile_and_load_on_refbackend(compiled)
# 调用ExecutionEngine.invoke("forward")方法,内部调用ExecutionEngine::lookupPacked("forward")获取相应可函数指针
jit_module.forward(torch.tensor([-1.0, 1.0, 0.0]).numpy())
# array([-0.7615941 0.7615941 0. ], dtype=float32)
下面以torch_mlir.compile函数为例,对torch-mlir全流程执行机制进行详细分析,要点描述如下,详细内容见图7所示。
- 与torch相关的MLIR转换和优化Pass注册机制:
PYBIND11_MODULE(_torchMlir, m)函数会在导入_torchMlir模块时自动调用。因为import torch_mlir涉及了_torchMlir模块的导入,所以在首次导入torch_mlir模块时即触发了与torch相关的MLIR转换和优化Pass的注册 - torch-mlir使用到的所有Dialects注册机制:TorchDialect中的Op定义是通过torch_ods_gen.py根据TorchScript的Op(
torch::jit::Operator)注册信息自动生成的,生成文件内容详见GeneratedTorchOps.td - 将TorchScript模型转换为TorchDialect IR的流程
- 对TorchDialect IR执行各种Pass优化的流程
- 将TorchDialect IR降低到Linalg-on-Tensors IR的流程

备注:
- mlir已使用pybind11对其核心类与功能进行了Python绑定,详见mlir/lib/Bindings/Python。外部项目若需要在自己的项目中使用这些Python绑定,只需要在CMakeLists.txt中使用如下命令即可完成:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 在torch_mlir中引入mlir_libs,其位于torch_mlir._mlir_libs
add_mlir_python_common_capi_library(TorchMLIRAggregateCAPI
INSTALL_COMPONENT TorchMLIRPythonModules
INSTALL_DESTINATION python_packages/torch_mlir/torch_mlir/_mlir_libs
OUTPUT_DIRECTORY "${TORCH_MLIR_PYTHON_PACKAGES_DIR}/torch_mlir/torch_mlir/_mlir_libs"
RELATIVE_INSTALL_ROOT "../../../.."
DECLARED_SOURCES ${_source_components}
)
# 设置torch_mlir Python模块
add_mlir_python_modules(TorchMLIRPythonModules
ROOT_PREFIX "${TORCH_MLIR_PYTHON_PACKAGES_DIR}/torch_mlir/torch_mlir"
INSTALL_PREFIX "python_packages/torch_mlir/torch_mlir"
DECLARED_SOURCES ${_source_components}
COMMON_CAPI_LINK_LIBS
TorchMLIRAggregateCAPI
)
名词解释
-
ODS: Operation Definition Specification:MLIR支持以表驱动的方式定义Operation和数据类型。使用TableGen记录简明定义Dialect中的Op,这些记录会在编译器构件时扩展为等价的
mlir::OpC++模板特化。 -
DRR: Declarative Rewrite Rule:与ODS类似,DRR是通过TableGen实现的,TableGen使用一种维护特定领域信息记录的语言。重写规则使用TableGen记录进行简明定义,并在编译器构建时扩展为等价的
mlir::RewritePattern子类。